Speculative MoE: 토큰·전문가를 미리 예측·배치해 MoE 추론 통신을 줄이기
ICML 2025 · arXiv:2503.04398 · DeepSeek-V2 / Mixtral-8x7B로 평가
🎯 한 문단 요약
대형 MoE를 여러 GPU에 쪼개 추론할 때, 전문가 병렬(EP)의 all-to-all 통신이 병목이다 —
가장 빠른 900GB/s 링크에서도 전문가 레이어 지연의 ~59%, 전체의 ~47%를 차지하고 느린 PCIe/이더넷에선 더 심하다.
Speculative MoE(s-MoE)는 발상을 바꿔, 각 토큰이 어느 전문가로 라우팅될지 미리 예측해서 토큰과 전문가를 같은 장치에 미리 모아둔다.
온라인 s-TS(토큰 사전 셔플)는 TP 단계의 allreduce를 맞춤 커널 shuffled-reduce-scatter로 바꿔 토큰을 예측 전문가 곁으로 끌어오고,
오프라인 s-EG(전문가 사전 그룹핑)는 같은 토큰에 함께 활성화되는 전문가들을 한 장치에 묶는다.
핵심 지표 로컬 활성화율(α)을 끌어올려 정확도·지연 손실 없이 통신량을 깎는다 →
DeepSpeed-MoE 대비 처리량 최대 6.5×↑.
※ "lossless" — 모델 로직·정확도를 건드리지 않고 통신만 줄인다. offloading처럼 지연을 늘리지도 않음. SGLang에도 이식돼 평균 1.68~1.97× 향상 → 범용 최적화.
★핵심 3대 질문
① 무슨 문제를 정의했나 · ② 무엇이 어려웠나 · ③ 어떤 구체적 방법으로 풀었나
① 어떤 문제를 정의했나
대형 MoE 추론에서 SOTA 프레임워크(DeepSpeed-MoE)의 진짜 병목인 EP의 all-to-all 통신을 줄이는 것. 토큰을 게이트(src)에서 담당 전문가(dst)로 보내고 다시 되돌리는 과정이 클러스터 전역 any-to-any 셔플을 만들어, 가장 빠른 링크에서도 전문가 레이어의 ~59%를 차지한다. 이걸 정확도·지연 손실 없이(lossless) 깎는 게 목표.
② 무엇이 어려웠나
- 통신이 본질적: dispatch+combine 두 번의 all-to-all이 토큰마다 필요 → 전역 셔플은 피하기 어렵다.
- 전문가 분산(dispersion): 작은 전문가가 많은 모델(DeepSeek-V2)은 한 토큰의 top-K 전문가가 여러 장치·서버에 흩어져 원격 통신이 커진다.
- 예측 실패 위험: 라우팅 경로를 잘못 예측하면 통신 절감이 안 된다 → 정확한 확률모델 필요.
- 제약: 정확도를 바꾸면 안 되고(lossless), offloading처럼 지연을 늘려도 안 됨. 게다가 전문가 재배치는 무거운 최적화+파라미터 이동이라 실시간엔 부적합.
③ 어떤 방법으로 풀었나
- 예측 기반 사전배치: 토큰-전문가 affinity를 프로파일링해, 토큰 자신(intra-layer)·이전 레이어 활성화(inter-layer)로 라우팅 경로를 89% 정확도로 예측.
- s-TS(온라인): TP의
allreduce를 맞춤shuffled-reduce-scatter로 대체해 토큰을 예측 전문가 곁으로 미리 셔플 → 로컬 활성화율↑, all-to-all 볼륨↓ (불필요한allgather1회도 제거). - s-EG(오프라인): 같은 토큰에 함께 켜지는 전문가들을 한 장치/서버에 co-clustering(0-1 ILP를 Cross-Entropy 최적화로 풀이) → 전문가 분산을 사전 차단.
1배경: MoE 추론과 EP 병목
MoE는 토큰마다 top-K 전문가만 켜는 희소 구조로, 파라미터는 키우되 연산은 sub-linear로 늘려 Gemini 1.5·Mixtral·DeepSeek-V3 등이 채택했다. 하지만 추론 시 거대한 전문가·어텐션 블록을 여러 GPU에 분산해야 하고, DeepSpeed-MoE는 3D 병렬(어텐션엔 TP·DP, 전문가엔 EP)을 쓴다.
EP(전문가 병렬)는 전문가를 GPU에 쪼개 병렬 계산하지만, 토큰 활성화를
게이트가 있는 임의의 GPU src에서 담당 전문가들 dst₁..dstK로 보내고(dispatch),
계산 후 다시 src로 되돌려(combine) KV 캐시와 합쳐야 한다. 이게 클러스터 전역 any-to-any 셔플을 만든다.
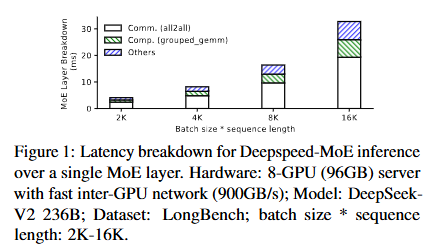
2왜 어려운가 + 핵심 관찰
통신을 줄이려면 "토큰을 담당 전문가와 같은 장치에 두는 비율"(=로컬 활성화율 α)을 높이면 된다. 하지만 라우팅은 게이트가 런타임에 결정하고, 작은 전문가가 많은 모델은 top-K가 여러 장치로 흩어진다. 두 가지 관찰이 돌파구가 됐다:
- intra-layer 토큰-전문가 conjugacy: 의미적으로 비슷한 토큰은 문맥과 무관하게 특정 전문가 소그룹을 켠다. 토큰의 활성화 맵 kurtosis가 대부분 8 이상 → 라우팅 대상이 좁게 집중. 토큰 자체만으로 top-K 전문가를 96.3% precision으로 예측 가능.
- inter-layer 전문가-전문가 affinity: 어떤 레이어에서 특정 전문가들을 고른 토큰은 다음 레이어에서도 거의 고정된 전문가 집합을 고른다. 이전 5개 레이어를 보면 다음 레이어를 ~70% 예측.
3핵심 아이디어: s-TS + s-EG
s-MoE는 정적·결정적 병렬화를 동적·예측적(speculative) 스킴으로 바꾼다. 두 메커니즘이 함께 로컬 활성화율을 끌어올린다.
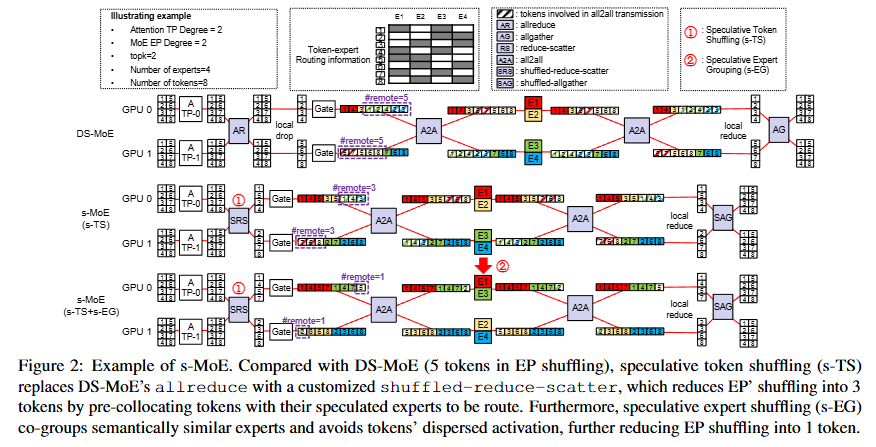
allreduce 후 전역 셔플 → 원격 5. s-TS: allreduce를 shuffled-reduce-scatter로 바꿔 토큰을 예측 전문가 곁으로 미리 모음 → 원격 3. s-TS+s-EG: 의미적으로 비슷한 전문가까지 같은 장치로 묶음 → 원격 1.3.1 s-TS — Speculative Token Shuffling (온라인)
- 게이트 이전에 각 토큰의 라우팅 전문가를 예측하고, 토큰을 그 전문가가 있는 장치로 미리 셔플해 EP의 all-to-all 볼륨을 줄인다.
- DeepSpeed-MoE TP의
allreduce를 맞춤 커널shuffled-reduce-scatter(SRS)로 재구성 — 토큰 셔플을reduce-scatter에 융합하고, 덤으로 비싼allgather1회를 제거. 되돌릴 땐shuffled-allgather(SAG). - 한계: 예측이 틀리거나 전문가가 여러 장치로 분산되면 절감이 줄어든다 → 정확한 확률모델(전자)과 s-EG(후자)로 보완.
3.2 s-EG — Speculative Expert Grouping (오프라인)
- 전문가 분산을 줄이려고, 같은 토큰(또는 의미적으로 가까운 토큰 무리)에 함께 활성화되는 전문가들을 같은 장치/서버에 사전 클러스터링한다.
- 클러스터링·전문가 재배치는 무거운 최적화+대량 파라미터 교환이 필요해 주기적으로 오프라인에서만 수행. 게이트 모듈을 열(column) 단위로 재배열해 투명하게 전문가를 섞고 다른 레이어 의미는 보존.
4예측 모델 & co-clustering
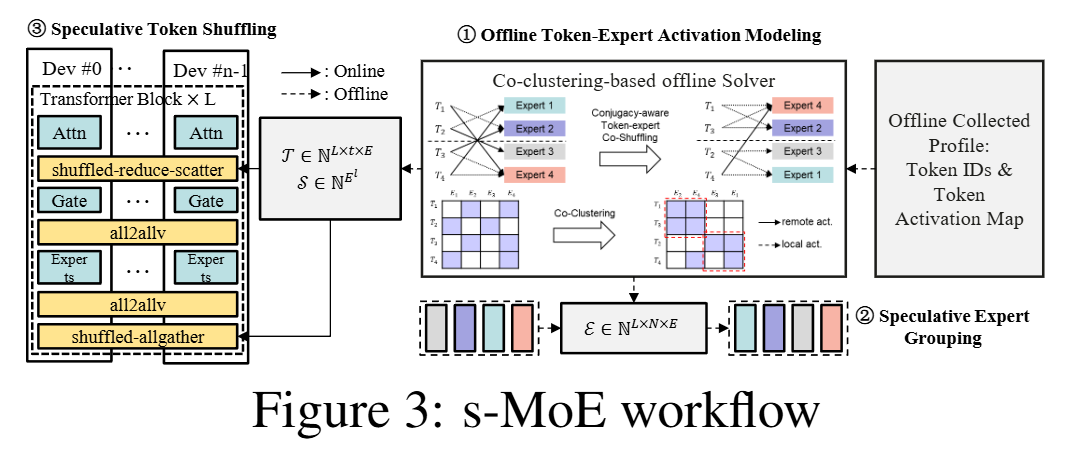
4.1 라우팅 경로 예측 (가벼운 룩업테이블)
- intra-layer: 토큰
x만으로 전문가 확률Pr(E_k|x)→ 토큰-전문가 신뢰도표C_p. 미등록(OOV) 토큰은 임베딩 공간에서 코사인 최근접 토큰으로 대체. - inter-layer: 장치 시퀀스를 n-gram(2-gram) 마르코프로 모델링 → 전문가클러스터열→클러스터 표
A. 둘 중 신뢰도 높은 쪽을 채택. - 룩업만 하면 끝 — 부하 계산·의사결정 없음. 테이블도 작다(예: DeepSeek-V2 토큰-장치표 ≈ 11.7MB).
4.2 균형 토큰-전문가 co-clustering (0-1 ILP)
토큰과 전문가를 E개 클러스터(=EP degree)에 배정하는 정수계획. 목적함수는 두 항의 가중합(θ):
- 부하 균형: 클러스터별 토큰 빈도를 고르게(EP rank 간 부하 균형).
- 원격 활성화 최소화: 서로 다른 클러스터에 속한 토큰-전문가 활성화 합을 최소화(=all-to-all↓).
- 각 토큰·전문가는 한 클러스터에만, 클러스터당 전문가 수는 동일(하드 제약).
이 ILP는 직접 풀기 어려워, s-MoE는 Cross-Entropy 최적화(CEO) 기반 2단계 알고리즘으로 빠르게 근사해(부하 균형 보장). METIS·2D Balanced KMeans보다 LAR +14.2%, 불균형률 −10.2% 우수.
5실험 결과
하드웨어 2종: Server-A(8×96GB HBM, 900GB/s 고속 동종망), Server-B(8×48GB, PCIe-5 63GB/s + UPI 20GB/s 느린 이종망). 모델: DeepSeek-V2(작은 전문가 다수)·Mixtral-8x7B(큰 전문가 소수). 데이터셋: LongBench·GSM8K·HumanEval. 워크로드: Mooncake·Azure 실트레이스. 지표: TTFT·TPOT·p90-TBT SLO 하 처리량.
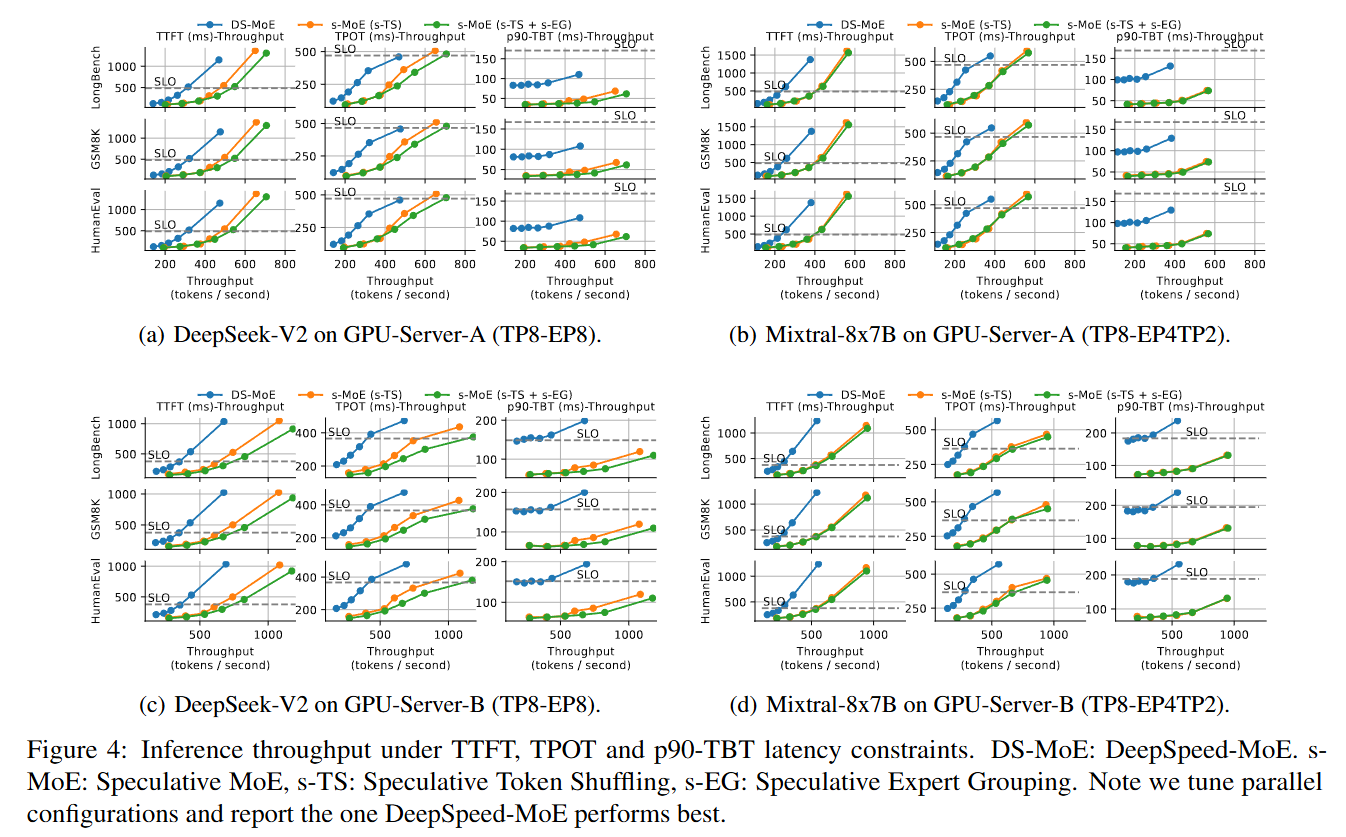
- vs DeepSpeed-MoE(s-TS+s-EG): 처리량 1.69~2.37× (TTFT), 1.14~2.93× (TPOT), 1.48~6.54× (p90-TBT).
- 기여도: s-TS가 향상의 평균 73%, s-EG가 27%(DeepSeek-V2). Mixtral은 전문가가 8개뿐이라 이미 집중적이어서 s-EG 효과는 ~4%로 작음(s-TS는 여전히 유효).
- 인터커넥트 민감도: 느린 Server-B에서 부스트가 훨씬 큼(예: DeepSeek-V2 p90-TBT 4.3×) → 경제형 추론 환경에 특히 유리.
- SGLang 이식: 평균 1.68× / 1.96× / 1.97×(TTFT/TPOT/p90-TBT) → DeepSpeed 전용이 아닌 범용 최적화.
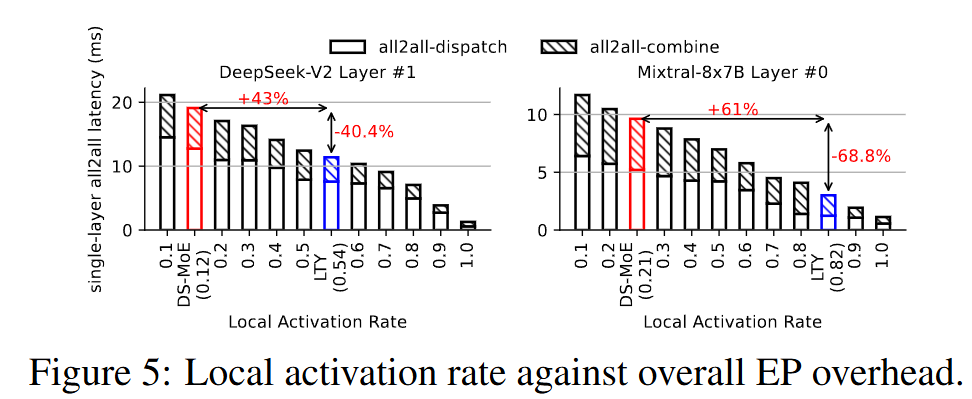
※ 이론상 100% 로컬은 불가능(서로 다른 토큰이 각자의 hot 전문가를 원해 충돌, GPU 메모리도 유한). 그래도 α를 크게 올리는 것만으로 통신을 대폭 절감.
6한계 & 의의
- 의의: MoE 추론 통신을 lossless하게(정확도·지연 손실 0) 줄인 첫 speculative 스킴. 기존 ExFlow가 inter-layer affinity만, Top-1만 다룬 것과 달리 intra/inter-layer + 토큰-전문가 conjugate affinity 셋 다를 활용해 토큰·전문가를 함께 스케줄. 모델 구조 수정 불필요(Pre-gated MoE와 대비).
- 실용성: ~5000 LOC + Triton 커널. DeepSpeed-MoE·SGLang 플러그인, vLLM·TensorRT-LLM 지원 예정. 엔지니어링 최적화(one-shot
all2allv·de-duplication·캐시 룩업)로 추가 ~7%. - 한계: ① 예측이 틀리면 절감↓ → 정확도(89%)에 의존, OOV·분포변화에 취약 가능. ② s-EG는 전문가 수가 적은 모델(Mixtral)엔 효과 미미. ③ s-EG 재그룹핑은 오프라인 비용·파라미터 이동이 있어 빈번한 적응엔 부적합. ④ 평가가 8-GPU 단일서버 규모 → 더 큰 멀티노드 클러스터 검증은 향후 과제.
7핵심 용어
EP (Expert Parallelism) — 전문가를 GPU에 분산. 토큰을 dispatch/combine하는 all-to-all 2회가 통신 병목.
all-to-all (all2all) — 모든 장치가 서로 토큰을 주고받는 집합통신. EP의 핵심 비용.
로컬 활성화율(α, LAR) — 토큰이 같은 GPU의 전문가로 라우팅되는 비율. 높을수록 원격 통신↓.
s-TS — Speculative Token Shuffling. 온라인에서 토큰을 예측 전문가 곁으로 미리 셔플(SRS/SAG 커널).
s-EG — Speculative Expert Grouping. 오프라인에서 함께 켜지는 전문가를 같은 장치에 사전 배치.
token-expert conjugacy — 비슷한 토큰↔특정 전문가 소그룹이 강하게 결합되는 양방향 군집성.
CEO (Cross-Entropy Optimization) — co-clustering ILP를 근사하는 몬테카를로 최적화.
TTFT / TPOT / p90-TBT — 첫 토큰 지연 / 출력토큰당 평균 지연 / 토큰간 지연 90퍼센타일. 추론 SLO 지표.
✎내 메모
이 논문을 읽고 떠오른 생각·질문·아이디어를 적어두세요. 이 기기 브라우저에 자동 저장됩니다.