SonicMoE: IO·타일 인식 최적화로 MoE 학습 가속하기
arXiv 2512.14080 · ICLR'26 · 코드: Dao-AILab/sonic-moe
🎯 한 문단 요약
최신 MoE는 전문가를 더 잘게(fine-grained), 더 희소하게(sparse) 만드는 추세인데, 이게 모델 품질은 올리지만 GPU에서는 메모리·IO 병목을 심하게 일으킨다. SonicMoE는 이 문제를 ① 역전파 메모리를 최소화하는 알고리즘, ② IO를 연산과 겹치는 GPU 커널, ③ 낭비 연산을 없애는 token rounding 라우팅의 3단으로 풀었다. 그 결과 H100에서 활성화 메모리 45% 감소, forward 연산량 43% 증가를 달성하고, 커널 전체를 오픈소스로 공개했다.
※ 64×H100에서 213B tokens/day로, ScatterMoE가 96×H100에서 내는 225B tokens/day와 맞먹는 학습 속도(= 약 1.5배 GPU 효율).
★핵심 3대 질문
① 무슨 문제를 정의했나 · ② 무엇이 어려웠나 · ③ 어떤 구체적 방법으로 풀었나
① 어떤 문제를 정의했나
최신 MoE는 fine-grained(전문가를 잘게)·sparse(전문가 수↑, 활성 수는 고정)로 갈수록 FLOP당 품질이 좋아진다. 그런데 바로 그 특성 때문에 GPU 학습이 비효율적이 된다. 이 논문이 정의한 문제: 이 추세를 따르는 MoE를, 정확도·FLOPs는 그대로 둔 채 활성화 메모리는 최소로·학습 처리량은 최대로 돌리는 커널/알고리즘을 만드는 것.
② 무엇이 어려웠나
- 메모리 폭증: granularity↑면 역전파용 활성화가 활성 전문가 수 K에 선형 증가.
- IO 병목: granularity·sparsity↑ → 산술강도↓ → memory-bound, IO 비용이 선형으로 늘고 숨기기 어려움.
- 연산 낭비: sparse하면 전문가당 토큰이 적어 Grouped GEMM 타일 패딩이 버려짐(tile quantization).
- 단순 해법의 부작용: 메모리를 더 줄이려 atomic-add로 중간변수를 없애면 결정론·수치정밀도·통신 호환성이 깨짐.
- 하드웨어 제약: 새 기능 활용이 까다로움(예: Blackwell 2-CTA에서 cp.async 완료신호가 CTA 경계를 못 넘음).
③ 어떤 방법으로 풀었나
- 메모리(알고리즘): 역전파 계산경로를 수학적으로 동등하게 재설계 → 큰 활성화
Y·dY를 캐싱하지 않고dS=⟨dA',A'⟩로 계산, gather를 HBM 로드와 융합. 결과 캐싱은2Td+4TKn(=같은 활성파라미터 dense 수준, 이론상 최소). - IO 숨기기(커널): gather fusion(fwd+bwd 모두), epilogue fusion(SwiGLU/dSwiGLU/dS/dH를 한 epilogue에서), MMA↔IO 오버랩(Hopper Ping-Pong / Blackwell TMEM 2단).
- 낭비 제거(라우팅): token rounding으로 전문가별 토큰 수를 타일(128) 배수로 반올림(전문가당 최대 1타일만 변경).
1배경: MoE와 두 가지 추세
MoE(Mixture of Experts)는 트랜스포머의 MLP 자리를 여러 개의 작은 "전문가(expert)" 네트워크로 바꾸고, 토큰마다 일부 전문가만 활성화하는 구조다. 덕분에 파라미터 수는 키우면서도 학습 FLOPs는 거의 안 늘릴 수 있다.
최근 모델(DeepSeek-V3, Qwen3-MoE, gpt-oss, Kimi K2 등)은 두 방향으로 진화 중이다:
- 고세분화(granularity↑): 전문가 하나의 중간 차원
n을 작게 → 전문가 개수를 늘림. 세분도G = d/n(임베딩차원/전문가차원). - 고희소(sparsity↑): 활성 전문가 수
K는 고정한 채 전체 전문가 수E만 늘림.
스케일링 법칙상 둘 다 FLOP당 품질을 높인다. 문제는 이게 하드웨어에서는 점점 비효율적이 된다는 것.
MoE 연산 = Grouped GEMM
각 전문가는 자기에게 라우팅된 토큰을 여기저기서 모아(gather) 행렬곱을 하고, 결과를 원위치로 흩뿌린다(scatter). 전문가마다 토큰 수가 달라서, 토큰 차원(M)만 가변인 "varlen-M Grouped GEMM"으로 계산한다.
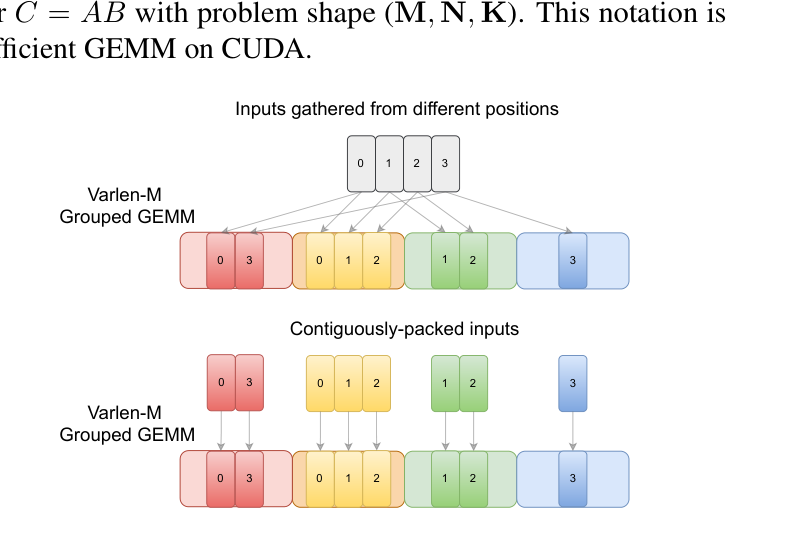
2왜 fine-grained·sparse MoE는 느려지나
핵심 지표는 산술 강도(arithmetic intensity) = FLOPs ÷ 전송 바이트(IO). 이 값이 낮으면 연산이 아니라 메모리 전송에 발목 잡히는(memory-bound) 상태다.
3 / ( (2+2G)/d + 3/(Tρ) )→ 세분도 G가 커지거나 희소도 때문에 ρ(=K/E)가 작아지면 산술 강도가 떨어진다. 즉 더 잘게·더 희소하게 갈수록 IO 비용이 선형으로 증가하며 memory-bound로 빨려 들어간다.
여기에 세 가지 구체적 손해가 겹친다:
- 활성화 메모리 폭증: 역전파용 활성화가 활성 전문가 수에 비례해 선형 증가 (ScatterMoE 등 기존 커널).
- IO 비용 증가·산술 강도 하락: 위 식 그대로.
- 타일 양자화(tile quantization) 낭비: 희소할수록 전문가당 토큰이 적어, Grouped GEMM 타일(예: 128) 패딩으로 버려지는 연산이 커짐.
3기여 ① 메모리 효율 알고리즘
아이디어: 역전파에 꼭 필요한 활성화만 캐싱한다. FLOPs를 늘리지 않으면서도 수학적으로 동등한 계산 경로를 새로 짜서, 메모리 큰 활성화를 저장하지 않는다.
- 크기
O(TKd)짜리 활성화(다운프로젝트 출력Y, 모은 입력Xe)는 캐싱하지 않음 → 메모리가 세분도에 비례해 늘지 않게 됨. - gather를 HBM 로드와 융합해
X·dO를 따로 물질화(materialize)하지 않음. - 라우터 기울기
dS와dH를Y·dY없이 계산하는 대체 경로를 유도 (부록 C). 핵심:dS = ⟨dA', A'⟩형태로 바꿔 2TKd 바이트의 추가 로드·캐싱을 제거.
X, H + 라우팅 메타데이터뿐 = 2Td + 4TKn 바이트.
이는 같은 활성 파라미터를 가진 dense 모델과 동일한, 재계산 없이 가능한 이론상 최소 활성화 메모리다.
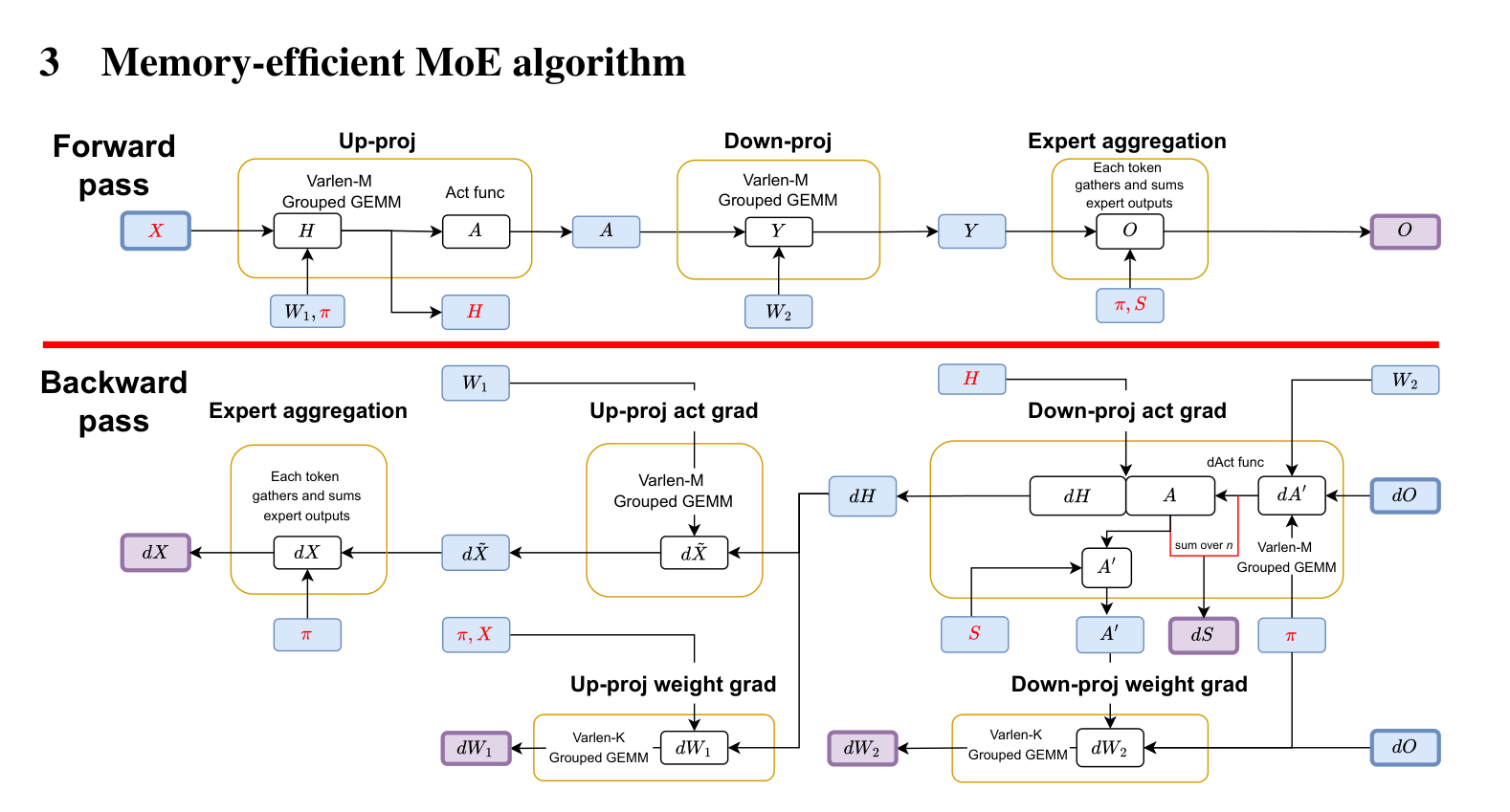
4기여 ② IO를 연산과 겹치는 커널
병목이 IO라면, IO 자체를 (1) 줄이고 (2) 연산 뒤에 숨기면(overlap) 된다. SonicMoE는 효율적인 varlen-M / varlen-K Grouped GEMM 위에 다음을 얹는다.
4.1 Gather 융합 (IO 절감)
토큰을 모으는 gather를 GMEM→SMEM 로드와 한 커널로 융합(cp.async 사용).
특히 역전파에서도 gather를 융합한 게 차별점 — ScatterMoE·MoMoE는 backward에서 별도 gather 커널을 띄운다.
이것만으로 2TKd 바이트의 IO를 아낀다.
Blackwell의 2-CTA 클러스터에서는 cp.async 완료 신호가 CTA 경계를 못 넘는 한계가 있어, 전용 "relay warp"로 신호를 중계한다(Figure 4).
4.2 Epilogue 융합
- SwiGLU / dSwiGLU를 GEMM epilogue에 융합.
dH커널 epilogue 하나에서dH,dS,A'를 한꺼번에 계산 → ScatterMoE가 3개로 나눠 하던 걸 하나로.
4.3 MMA ↔ IO 오버랩 (핵심)
무거운 epilogue를 연산으로 가리는 게 관건이다.
- Hopper: 두 consumer warpgroup이 번갈아 한쪽은 GEMM, 한쪽은 IO를 하는 Ping-Pong 스케줄링 + 비동기 TMA load/store.
- Blackwell: TMEM(온칩 256KB, 128×512)을 256열씩 2단으로 나눠, 한 단이 UMMA로 누적하는 동안 다른 단이 epilogue 실행.

기존 커널과 비교
| 기능 | SonicMoE | ScatterMoE | MoMoE |
|---|---|---|---|
| Gather를 로드와 융합 (fwd/bwd) | ✓ / ✓ | ✓ / ✗ | ✓ / ✗ |
| dS = ⟨dA',A'⟩ (저메모리) | ✓ | ✗ | ✗ |
| dH·dS 동시 계산 epilogue | ✓ | ✗ | ✗ |
| MMA ↔ IO 오버랩 | ✓ | ✗ | ✗ |
5기여 ③ Token Rounding 라우팅
GEMM은 타일(예: Mtile=128) 단위로 계산해서, 전문가가 받은 토큰 수가 타일 배수가 아니면
패딩으로 버려지는 연산이 생긴다. 희소할수록 전문가당 토큰이 적어 이 낭비가 커진다.
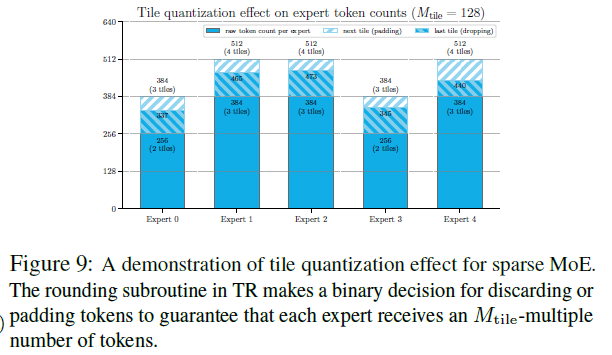
Token Rounding(TR)은 2단계 정렬로 동작한다(Algorithm 4):
- ① 일반 top-K token-choice 라우팅을 먼저 계산.
- ② 전문가별로 점수 정렬 후, 받은 토큰 수를 가장 가까운 Mtile 배수로 반올림 — 모자라면 점수 높은 토큰을 채우고(pad), 넘치면 낮은 토큰을 버린다(drop).
학습은 TR로 하고 추론 때는 그냥 일반 top-K로 바꿔도 품질이 유지된다(별도 적응 불필요).
T̄e/Mtile ≥ 2이면 안정적. 고희소 영역에서 커널 실행 기준 +16% TFLOPS.
6실험 결과
전체 그림 한 장
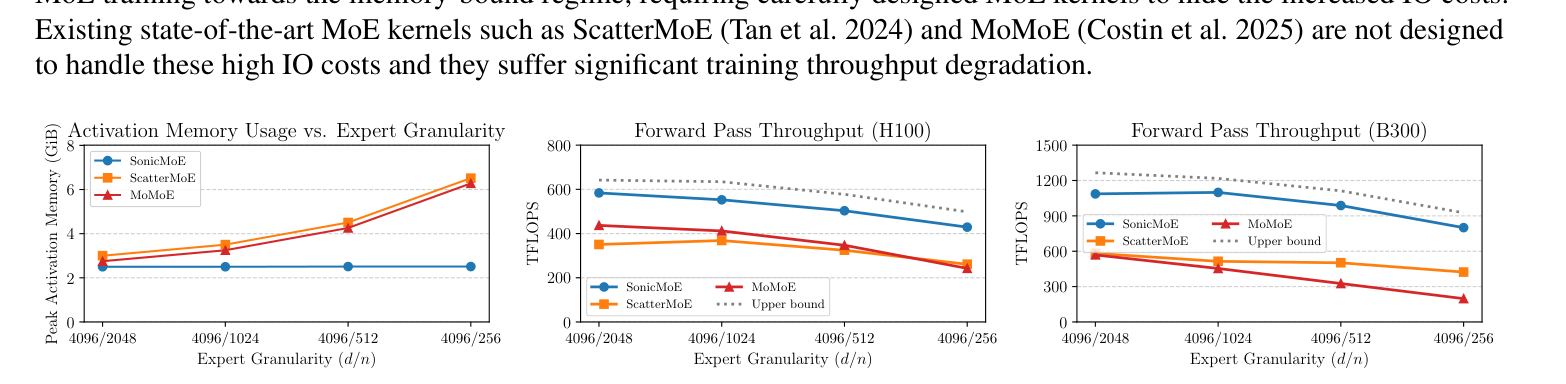
① 활성화 메모리
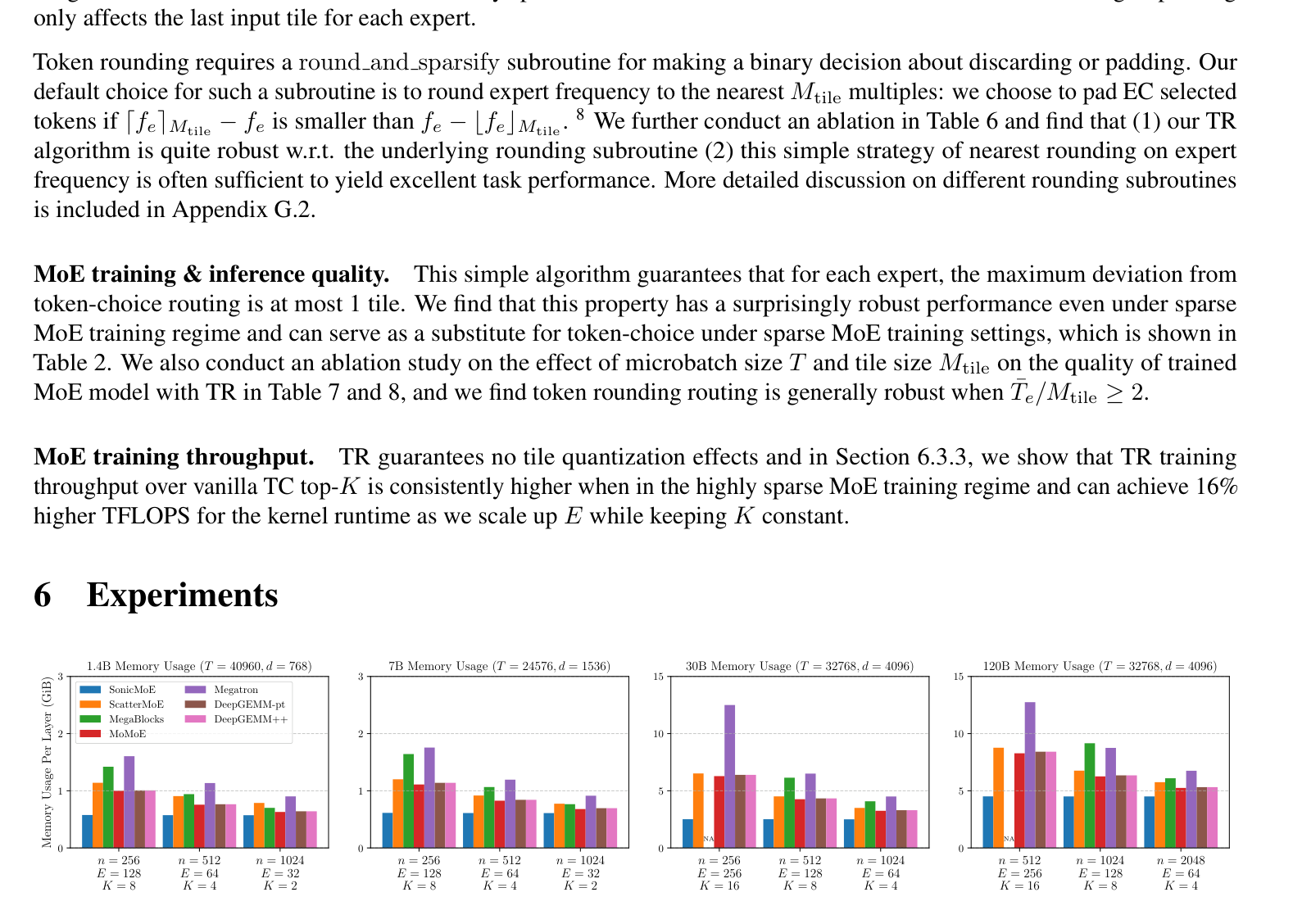
모든 규모(1.4B~120B)에서 가장 낮은 층당 피크 메모리. 7B(n=256)에서 ScatterMoE 대비 45%↓, 120B에서는 MoMoE 대비 층당 3GiB 이상 절약. 세분도가 올라가도 메모리가 안 늘어나는 게 핵심.
② 연산 처리량 (커널 단위)
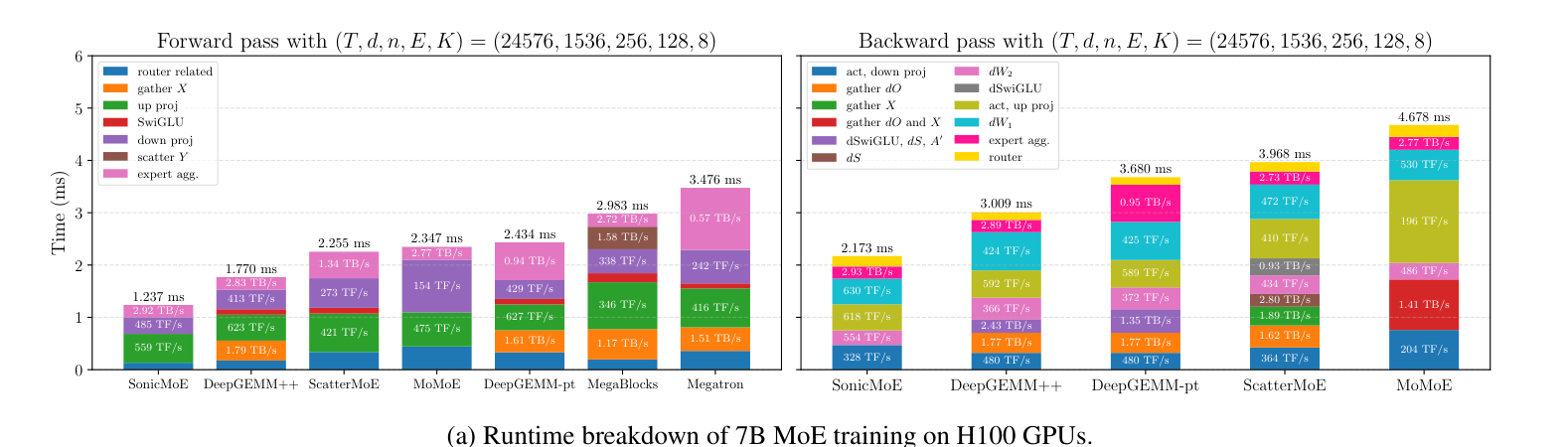
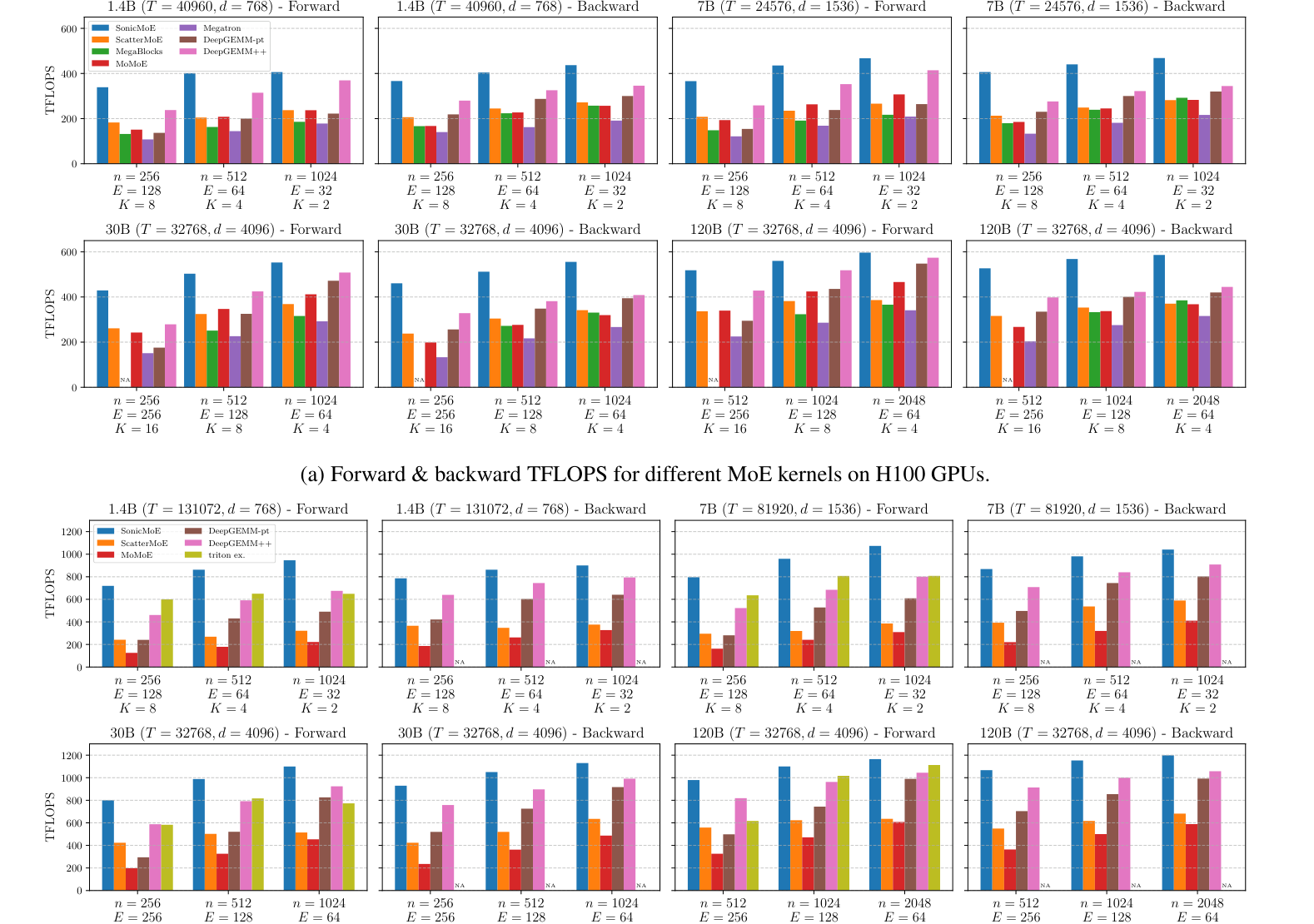
B300(Blackwell)에서도 OLMoE급 7B에서 DeepGEMM++ 대비 forward +25%, backward +15%. 또 ScatterMoE·MoMoE·DeepGEMM이 전부 OOM/오버플로로 못 돌리는 DeepSeek-V3.2-Exp(685B) 설정도 SonicMoE는 단일 H100에서 동작.
③ 실제 학습 처리량
→ GPU를 33% 적게 쓰고도 비슷한 속도. (FSDP-2 / ZeRO-3, lm-engine 코드베이스)
④ Token rounding 품질
0.5B·1.4B 모델에서 TR로 학습 후 top-K로 추론해도 token-choice와 동등하거나 더 나은 다운스트림 평균 정확도. expert-choice(EC)는 인과성 누설로 train-val gap이 큰 반면, TR은 gap이 작고 task 성능도 항상 우위.
7한계 & 의의
- 의의: "더 잘게·더 희소하게"라는 MoE 추세가 만드는 하드웨어 비효율을, 알고리즘·커널·라우팅을 함께(co-design) 풀어 메모리와 속도를 동시에 잡았다. CuTe-DSL 기반 + PyTorch 인터페이스로 오픈소스.
- 실용 포인트: ①②는 라우팅을 안 바꿔도 그대로 적용 가능(드롭인). ③ token rounding은 고희소 학습에 추가로 얹는 옵션.
- 한계/주의: 임시 변수
Y는 여전히 물질화(층 수 > K면 무시 가능). 결정론·수치정밀도·통신 호환성 문제로 atomic-add식 완전 제거는 피함. TR은T̄e/Mtile = 1처럼 극단적으로 토큰이 적으면 품질 저하 가능(그래도 EC보다는 나음). 최적화가 Hopper/Blackwell 세대 기능에 특화돼 있음.
8핵심 용어
Granularity(세분도) G = d/n — 임베딩 차원 ÷ 전문가 중간 차원. 클수록 전문가가 잘게 쪼개짐.
Sparsity(희소도) — 전체 전문가 E 중 활성 K만 사용. ρ = K/E.
Grouped GEMM — 크기가 제각각인 여러 행렬곱 묶음. 토큰 차원만 가변이면 varlen-M.
Arithmetic intensity(산술 강도) — FLOPs/IO. 낮으면 memory-bound.
Epilogue — GEMM 뒤처리 단계(활성화 함수, HBM 저장 등).
TMA / cp.async — GPU의 비동기 메모리 전송 명령. IO를 연산과 겹치는 데 사용.
Tile quantization — 타일 배수로 패딩하며 생기는 낭비 연산.
TMEM — Blackwell의 온칩 텐서 메모리(누적 결과 저장용).