Linear Layouts: F₂ 선형대수로 텐서 연산 코드를 견고하게 생성하기
ASPLOS '26 · 10.1145/3760250.3762221 · Triton에 통합
🎯 한 문단 요약
텐서 layout(논리 텐서 ↔ GPU 레지스터/스레드/워프/메모리 매핑)은 GPU 커널 성능의 핵심인데, 기존 컴파일러는 layout마다 케이스별로 손코딩해서 layout 종류가 늘면 변환 경우의 수가 제곱으로 폭증하고 버그가 잦다. 이 논문은 layout을 F₂(0/1) 위의 선형사상 = 이진행렬로 모델링한다. 그러면 layout 변환이 행렬곱·역행렬로 일반화되고, swizzling·broadcast는 XOR/AND로 자연히 표현된다. Triton 백엔드에 통합해 다수 버그를 고치고 코드도 단순화했으며, 실제 265개 벤치 평균 1.07×·최대 1.40× 가속을 얻었다.
※ 동기: Triton GitHub 버그의 약 12%가 layout 관련일 만큼 기존 방식은 깨지기 쉬웠다.
★핵심 3대 질문
① 무슨 문제를 정의했나 · ② 무엇이 어려웠나 · ③ 어떤 구체적 방법으로 풀었나
① 어떤 문제를 정의했나
딥러닝 텐서 연산에서 tensor layout(논리 텐서를 하드웨어 자원에 어떻게 펼칠지)을 유연하면서도 효율적으로 정의·변환하는 일반적 방법이 없다. 기존 컴파일러(TVM/XLA/Triton)는 layout을 백엔드의 특수 속성으로 케이스별 구현 → 새 layout 추가가 어렵고 변환 조합이 폭증.
② 무엇이 어려웠나
- 제곱 폭증: layout이 N종이면 layout↔layout 변환이 최대 N² 가지 → 손으로 다 못 짬.
- 버그 양산: 인덱싱·변환을 layout마다 직접 구현 → Triton 버그의 ~12%가 layout 관련.
- 통일된 형식 필요: swizzling 같은 복잡한 데이터 재배치까지 하나의 형식으로 표현해야.
- HW 최적화 연결: 벡터화, bank conflict 회피,
ldmatrix/warp shuffle 같은 프리미티브와 매끄럽게 이어져야.
③ 어떤 방법으로 풀었나
- 표현 통일: 모든 layout을
F₂위의 이진행렬(하드웨어 비트 → 논리 텐서 비트)로 모델링. - 변환 일반화: 임의 변환을
B⁻¹∘A같은 행렬곱·역행렬로 — N² 손코딩 제거. swizzle/broadcast는 XOR/AND. - 자동 알고리즘: 최적 swizzling 자동 탐색(벡터화 최대·bank conflict 최소, 증명 가능), warp-shuffle 자동 생성, HW intrinsic 일반 lowering.
- 실배포: Triton GPU 백엔드에 완전 통합, 다수 기존 버그 수정 + 백엔드 코드 단순화.
1배경: tensor layout이란?
Layout은 논리 텐서의 각 원소를 어느 워프(w)·스레드(t)·레지스터(r)(또는 어느 공유메모리 위치)에 둘지 정하는 매핑이다. 같은 텐서라도 layout에 따라 메모리 접근 효율(coalescing)·연산 효율이 크게 달라진다.
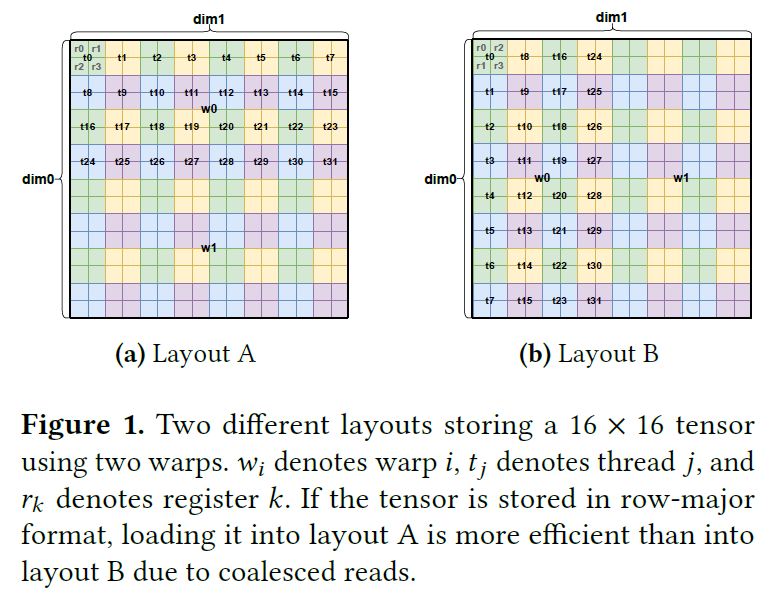
문제는 하드웨어가 다양해질수록 layout이 폭증한다는 것 — NVIDIA의 Tensor Core는 Ampere/Hopper/Blackwell마다, 자료형마다 다른 layout을 요구하고, AMD·Intel도 제각각이다. 게다가 메모리 접근에 좋은 layout과 연산(MMA)에 좋은 layout이 달라서, 둘 사이를 끊임없이 변환해야 한다.
2핵심 아이디어: layout = F₂ 위의 행렬
GPU의 거의 모든 수가 2의 거듭제곱이다(워프=32스레드, 워프그룹=4워프, MMA 타일=16×n…). 그래서 좌표를 비트로 보면, 하드웨어 인덱스 비트에서 논리 텐서 좌표 비트로 가는 매핑을 F₂(0/1, 덧셈=XOR, 곱셈=AND) 위의 선형사상으로 쓸 수 있다.
w = A·v (모든 연산은 F₂에서: 곱=AND, 합=XOR)
예: 워프 w0·스레드 t9·레지스터 r1의 위치는 각 요소의 좌표를 XOR하면 나온다 → (2,3). 이렇게 layout 하나가 행렬 하나가 된다.
- 합성/분해 = 행렬곱 / 블록대각·좌나눗셈(Definition 4.2~4.4)
- 역변환 = 역행렬(가우스 소거, Definition 4.5) → 하드웨어 인덱스 ↔ 논리 좌표 왕복
- layout A→B 변환 =
B⁻¹∘A한 줄로 일반화 (N² 손코딩 소멸) - swizzling·broadcast = 비트의 XOR/AND 조합으로 자연 표현
3모든 layout을 하나의 가족으로
Triton의 레거시 layout들은 종류마다 인터페이스를 따로 구현해야 했다. 이 논문은 그 모두가 linear layout의 특수 사례임을 증명한다.
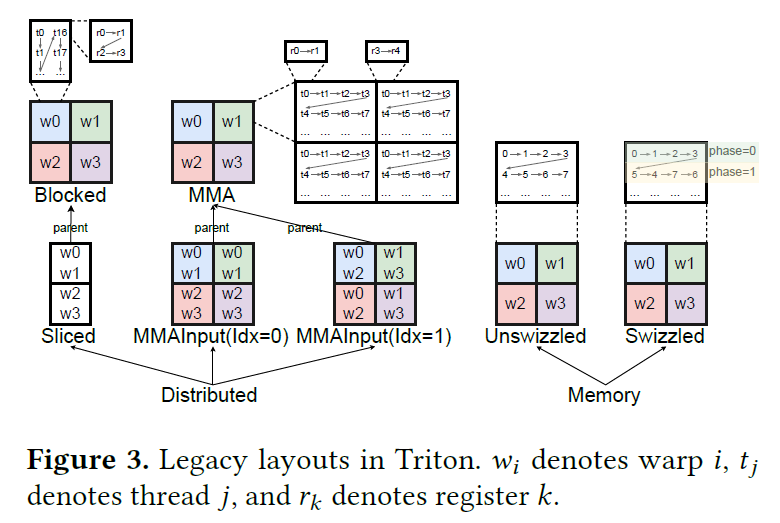
- Distributed layout (정리 4.9): 각 열에 1-비트가 최대 1개인 surjective 선형사상 = "0 열이 섞인 순열행렬". Blocked·MMA·Sliced가 전부 여기 속함.
- Memory layout (정리 4.13): 열에 1-비트가 1~2개인 가역 선형사상. Unswizzled·Swizzled(=mma swizzling) 포함.
이 통일 덕분에 shape 연산(transpose·reshape·broadcast 등)에서 layout이 닫혀(closed) 있어, 불필요한 변환 없이 자동 전파된다. 레거시에선 표현 못 하던 "MMA layout의 transpose"도 자연히 포함된다.
4코드 생성: 행렬연산으로 최적화
layout이 행렬이 되면, 그동안 손으로 하던 최적화들이 대수 연산으로 풀린다.
- 벡터화(연속 원소): 역행렬에서 레지스터가 항등으로 매핑되는 최대 블록을 찾으면 됨 → 여러 차원에 걸친 연속성도 포착(레거시는 마지막 차원이 1이면 벡터화 포기).
- broadcasting: 중복 데이터를 든 스레드/워프 식별 = 행렬의 0 열 찾기로 단순화(오랜 버그 원인 해소).
- 혼합정밀(mxfp4×bf16): scale broadcast를 shape 연산으로 표현하면 layout 엔진이 자동 처리. Machete가 수천 줄+CUTLASS로 하던 데이터 셔플 최적화를 파이썬 5줄로.
- SIMD 프리미티브:
L/ℓT(좌나눗셈)가 존재하면ldmatrix/stmatrix등으로 lowering 가능(정리 5.1). - gather: 축이 한 워프 안에 있으면 warp shuffle로 최적화.
warp shuffle로 layout 변환 (공유메모리 우회)
변환 B⁻¹∘A의 워프 성분이 항등이면, 공유메모리를 거치지 않고 warp shuffle만으로 스레드 간 교환이 가능하다. 교환할 원소들을 부분공간 basis(V∪I∪G)로 잡아 라운드별로 셔플한다(FlashAttention-3가 손으로 하던 최적화를 일반화).
최적 swizzling: bank conflict 제거 (Fig 5 — 요청하신 부분)
GPU 공유메모리는 여러 bank로 나뉜다. 한 메모리 트랜잭션에서 여러 스레드가 같은 bank의 다른 주소를 접근하면 bank conflict가 나서 접근이 직렬화 → 느려진다. 해법은 데이터를 비트 XOR로 재배치하는 swizzling이다.
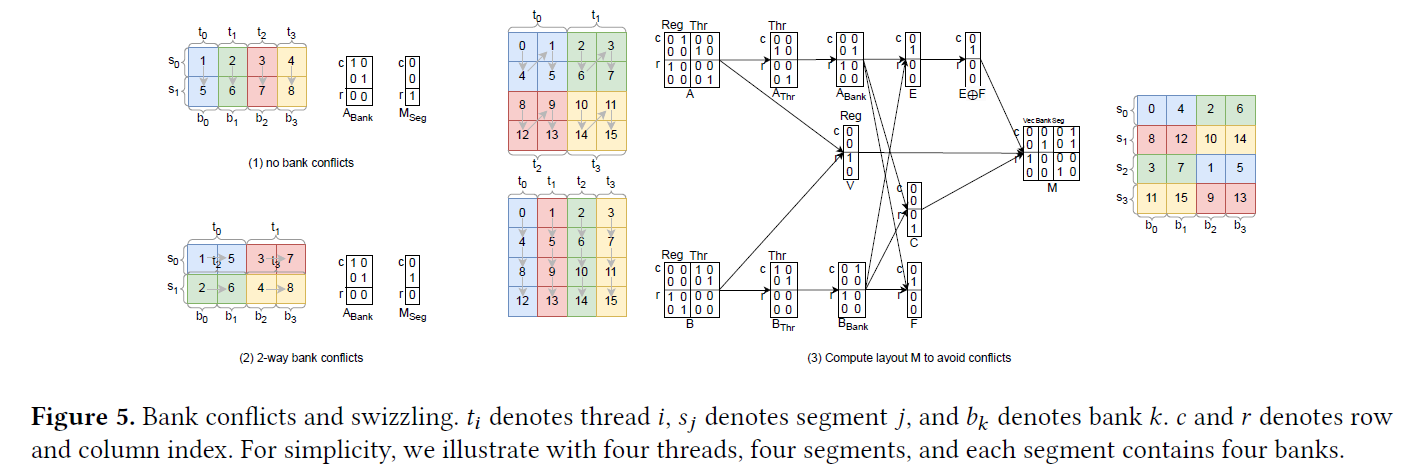
이 논문은 임의 linear layout에 대해 벡터화는 최대, bank conflict는 최소가 되는 swizzled layout M을 자동 계산하는 알고리즘을 제시한다(증명 포함). 직관:
- 벡터화 집합
V=A_Reg ∩ B_Reg의 basis로 한 번에 옮길 원소 크기를 키운다. - 같은 bank가 서로 다른 스레드에 가도록,
P=span(Vec∪Bank)와 교집합이 0인 가장 큰 부분공간H(=e_i⊕f_i기반)를 골라 segment 축M_Seg를 구성. - 결과
M은 읽기·쓰기 모두에서 충돌 없이 최대 벡터화 — Fig 5(3)처럼 4개 트랜잭션으로 깔끔히 분리된다.
5실험 결과
플랫폼: NVIDIA RTX4090 / GH200, AMD MI250. baseline = linear layout을 안 쓴 기존 Triton(레거시 layout).
정확성·효율 (마이크로벤치)
| 항목 | 기존 Triton | Triton-Linear |
|---|---|---|
| 로드/스토어 비트폭 (예: [512,2]×f8) | 16-bit | 128-bit (최대 7×↑) |
| 공유메모리 명령 수 (Blocked reduction) | 5888 | 1388 (−76%) |
| 혼합정밀 matmul pass rate (784 케이스) | 46.6% | 100% |
| MMA Input / Sliced<MMA> / Custom layout | 미지원(0) | 전부 통과 |
속도(마이크로): layout 변환 최대 3.93×, gather 최대 14.20×(공유메모리 우회), mxfp4×f16 혼합정밀 1.87×. gather는 축이 너무 커지면 셔플 라운드 오버헤드로 이득이 줄기도 함.
실제 워크로드 (TritonBench, 265 케이스)
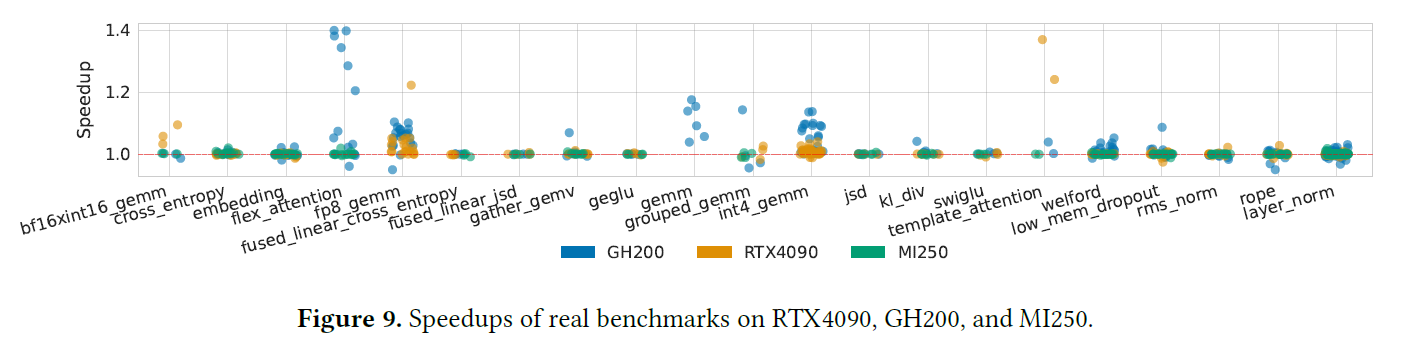
- 이득의 원천:
ldmatrix/stmatrix를 활용한 layout 변환·공유메모리 접근 최적화, "동등 layout" 변환을 no-op으로 제거. - AMD(MI250)는
ldmatrix같은 프리미티브가 없어 이득이 작음(1.00~1.03×). - 1.0 미만은 대부분 작은 입력의 측정 잡음.
6한계 & 의의
- 의의: layout을 1급 시민으로 끌어올려, 케이스별 손코딩과 N² 변환 폭증을 선형대수 하나로 대체. 새 layout/백엔드(예: out-of-tree Intel GPU)도 코어 수정 없이 추가 가능. 실제 Triton에 통합되어 버그 수정 + 코드 단순화.
- 한계: 모든 차원·분할이 2의 거듭제곱이라는 가정에 기반(F₂ 비트 표현의 전제). 또 효율 이득은
ldmatrix등 HW 프리미티브가 있는 NVIDIA에서 크고, 그것이 없는 AMD에선 작다.
7핵심 용어
Tensor layout — 논리 텐서 원소 ↔ 워프/스레드/레지스터/메모리 위치의 매핑.
F₂ — 원소가 {0,1}인 체. 덧셈=XOR, 곱셈=AND. 비트 연산과 1:1이라 HW에 효율적.
Distributed / Memory layout — 자원에 분산 vs 특수 메모리에 저장.
Coalescing — 인접 스레드가 인접 메모리를 읽어 한 번에 처리(대역폭↑).
Swizzling — 비트 XOR로 데이터를 재배치해 bank conflict를 피하는 기법.
Bank conflict — 한 트랜잭션에서 여러 스레드가 같은 공유메모리 bank를 접근 → 직렬화.
MMA / wgmma / ldmatrix — Tensor Core 행렬곱·행렬 로드 같은 특수 명령(특정 layout 요구).
warp shuffle — 같은 워프 내 스레드끼리 레지스터 값을 직접 교환(공유메모리 불필요).