Hydra: 전문가 인기도를 활용해 칩렛 시스템에서 MoE 추론을 가속하기
DAC 2025 (62nd ACM/IEEE Design Automation Conference) · HW/SW 코디자인 · 22 nm 칩렛 가속기
🎯 한 문단 요약
MoE는 희소 게이팅으로 LLM을 키우지만, 칩렛(MCM)에 올리면 두 가지 새 병목이 생긴다 — 전문가들이 칩렛에 흩어져 토큰을 주고받는 all-to-all 통신(MoE layer 런타임의 최대 74.9%)과, (un)permutation·gating의 비효율 연산(평균 62.7%). Hydra는 이를 SW·HW 코디자인으로 동시에 푼다. SW에서는 인접 layer 간 전문가 선택의 상관성을 이용해 다음 layer의 전문가 인기도를 미리 예측하고, 인기 전문가를 토큰이 몰린 칩렛 근처에 배치하는 popularity-aware 매핑(simulated annealing)으로 통신을 줄인다. HW에서는 CAM 병렬검색으로 O(S²M) sparse matmul permutation을 O(E)+S번 이동으로 대체하고, softmax skipping으로 불필요한 지수·나눗셈을 제거한다. 22 nm 4×4 칩렛으로 GPU(RTX 3090) 대비 지연 14.2×↓·전력 169.1×↓, SOTA MoE 가속기(FLAME) 대비 지연 3.5×↓·전력 18.9×↓. 정확도 손실 없음.
※ 핵심: 라우팅은 런타임에 동적으로 결정되지만 layer 간 전문가 선택이 상관되어 있어, 직전 layer 결과로 다음 layer 인기도를 예측해 weight 로딩과 겹쳐(prefetch) 매핑을 미리 최적화할 수 있다는 게 발상의 핵심.
★핵심 3대 질문
① 무슨 문제를 정의했나 · ② 무엇이 어려웠나 · ③ 어떤 구체적 방법으로 풀었나
① 어떤 문제를 정의했나
칩렛 기반(MCM) 시스템에 MoE를 효율적으로 올리는 것. 구체적으로 칩렛 간 all-to-all 통신과 MoE layer 내부의 비효율 연산(permutation·gating)이라는 두 병목을 동시에 제거해 추론 지연·전력을 낮추는 것. 그것도 정확도 손실 없이(lossless) 달성하는 것이 목표.
② 무엇이 어려웠나
- 통신 병목: all-to-all이 MoE layer 런타임의 최대 74.9%. 게다가 라우팅이 일부 전문가(E0·E1)로 편향(skewed)되어 특정 칩렛에 트래픽이 몰림.
- 동적 라우팅: 어떤 전문가가 인기일지는 런타임에야 결정됨. 실시간 게이팅 결과를 보고 매핑을 바꾸면 weight 로딩과 겹칠 수 없어 오히려 느려진다 → 사전 예측이 필요.
- 연산 비효율: (un)permutation은 sparse matmul이라
O(S²M), softmax는 지수·나눗셈이 비쌈. 통신 빼고 보면 (un)perm+gating이 런타임의 평균 62.7%. - 무손실 제약: token-drop·근사 라우팅 같은 기존 통신 절감책은 모델 성능을 해친다 → 정확도를 건드리지 않아야 함.
③ 어떤 방법으로 풀었나
- 인기도 예측 + popularity-aware 매핑(SW): 인접 layer 간 전문가 선택의 조건부 확률(상관성)로 다음 layer 인기도를 미리 예측 → 인기 전문가를 토큰이 몰린 칩렛 근처에 두도록 simulated annealing으로 매핑 최적화(통신 hop 최소화).
- CAM 기반 permutation 엔진(HW): 전문가 인덱스를 CAM에 쓰고 병렬 검색으로 token↔expert 매핑을 만들어,
O(S²M)sparse matmul을O(E)검색 + S번 데이터 이동으로 대체. - Redundant-skipping softmax 엔진(HW): token-wise(모델병렬 그룹 내 동일 토큰은 1/MP만 계산) + expert-wise(argmax로 뽑힌 전문가 외엔 나눗셈 skip) 스킵으로 지수·나눗셈 redundancy 제거(무손실).
1배경: 칩렛 위의 MoE
MoE(Mixture-of-Experts)는 Transformer의 FFN을 여러 전문가로 나누고, 게이트가 각 토큰을 일부 전문가에만 보내는 희소 구조다. 파라미터는 키우되 연산은 조금만 늘려 LLM 확장의 핵심이 됐다. 하지만 모델이 커지면 온칩 메모리 한계로 단일 칩에 다 못 올린다.
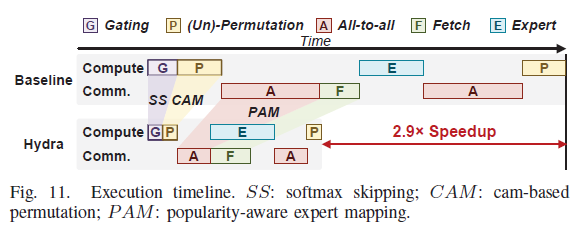
그 대안이 멀티 칩렛 모듈(MCM): 작은 칩렛 여러 개를 인터포저로 연결해 용량을 늘리고, 전문가 병렬(EP)로 전문가들을 칩렛에 흩는다. 대신 MoE layer는 4단계 — ❶Gating → ❷Permutation → ❸Computation → ❹Un-permutation — 를 거치고, 전문가가 다른 칩렛에 있으면 토큰을 보내고(dispatch) 받아오는(gather) all-to-all 통신 2회가 필요하다.
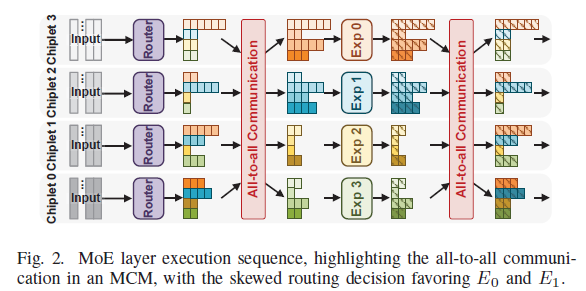
2왜 어려운가 (두 가지 병목)
2.1 All-to-all 통신
이 통신 패턴은 네트워크 혼잡을 일으켜 MoE layer 런타임의 최대 74.9%를 차지하는 주 병목으로 알려져 있다. 기존엔 device-limited·topology-aware 라우팅이나 token-dropping으로 통신을 줄였지만, 이는 모델 성능을 떨어뜨리고 추가 학습 오버헤드를 낸다. 또한 라우팅 결정이 런타임에야 정해져 실시간으로 매핑을 바꾸면 weight 로딩과 겹칠 수 없어 손해다.
2.2 비효율 연산
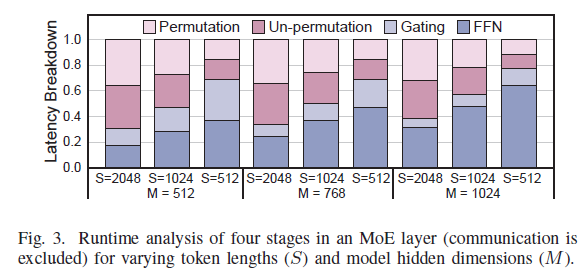
(S×S)×(S×M)이라 복잡도 O(S²M). 데이터 복제로 layout을 바꿔도 O(S²M/E)로 여전히 무겁다.gating의 softmax는 지수·나눗셈이 지배적인데 거의 최적화된 적이 없다.
3SW: 인기도 인식 전문가 매핑
아이디어는 단순하다 — 인기 전문가를 토큰이 많이 몰린 칩렛 가까이 두면, 더 많은 토큰이 원래 칩렛에 머물러(stay) 칩렛 간 전송이 줄어든다.
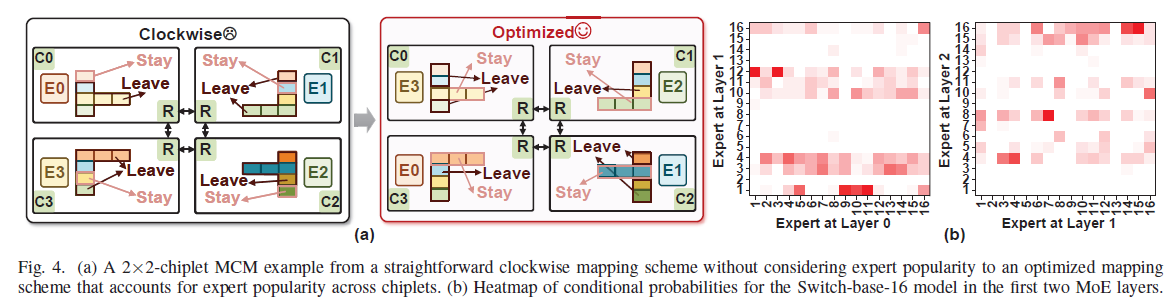
3.1 전문가 인기도 예측
C4 데이터셋 20만 토큰의 라우팅을 추적해 layer 간 전문가 선택의 조건부확률을 구했다. 다음 layer 전문가의 인기도는:
실시간 정보(직전 layer 결과)와 사전 통계(조건부확률)를 곱해 다음 layer 인기도를 미리 안다 → 매핑·prefetch를 weight 로딩과 겹칠 수 있다.
3.2 매핑 = 조합 최적화 (simulated annealing)
예측 인기도를 바탕으로 전문가↔칩렛 매핑을 통신비 최소화 문제로 푼다.
조합 최적화라 simulated annealing(Algorithm 1)으로 푼다: 무작위 배치에서 시작 → 두 전문가를 swap → 비용이 줄면 채택, 온도를 식히며 반복. 이 solver는 Hydra 칩렛에 내장되어, layer n 추론 중 외부 메모리가 layer n+1 전문가를 미리 가져온다(계산-메모리 접근 오버랩).
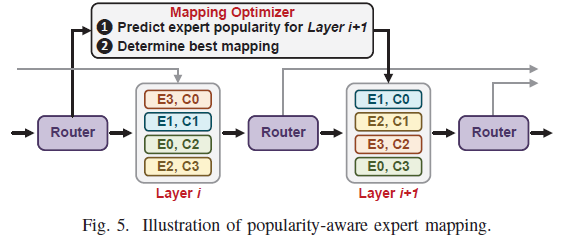
i의 실시간 라우팅 결과를 mapping optimizer에 넘기면 → ❶ layer i+1 인기도 예측 → ❷ 최적 매핑 결정 → 그 매핑대로 layer i+1 전문가를 칩렛에 재배치. 추론과 매핑/prefetch가 layer 단위로 파이프라인된다.4HW: CAM 기반 permutation 엔진
Hydra 칩렛은 2×2 그리드(확장 가능)로 묶이고, 각 칩렛은 16개 PE array·글로벌 SRAM 버퍼·softmax 엔진·CAM permutation 엔진·mapping solver를 갖춘다.
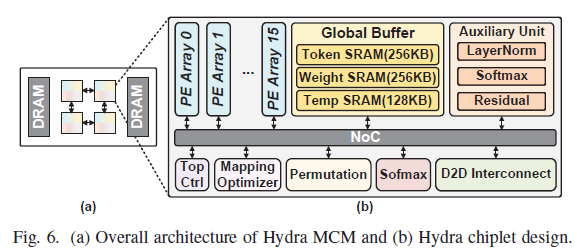
이 절의 핵심은 그중 permutation 엔진이다. (un)permutation은 토큰을 전문가별로 재배열하는데, 기존엔 sparse matmul이라 O(S²M)로 비싸다. Hydra는 이를 CAM(Content Addressable Memory) 병렬검색으로 대체한다.
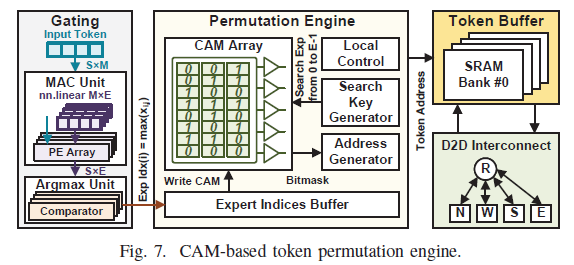
O(E)뿐. 매핑 테이블만 만들면 단 S번의 데이터 이동으로 permutation/un-permutation을 끝낸다. sparse matmul과 중간결과 저장이 통째로 사라져 지연·에너지가 크게 준다.
9T NAND형 CAM(6T SRAM + NAND 로직) 사용. CAM은 디지털 회로보다 병렬검색이 훨씬 에너지 효율적이라, 검색 오버헤드가 MoE의 대량 MAC 연산에 비해 무시할 수준이다.
5HW: 중복 제거 softmax 엔진
softmax는 S×E 행렬의 지수를 모두 구하고 행별 합으로 나눈다. Hydra는 두 종류의 중복을 찾아 건너뛴다(둘 다 무손실).
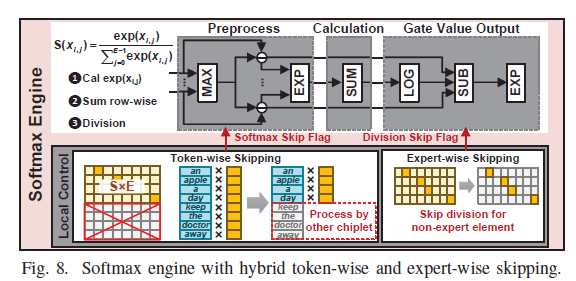
- Token-wise skipping(정적): 모델병렬(MP) all-reduce 때문에 같은 그룹 칩렛들은 MoE layer 진입 시 입력 토큰이 동일하다. 그러니 각 칩렛이
1/MP만 계산 — 배치 시점에 정해지는 정적 최적화. - Expert-wise skipping(동적): 게이팅은 결국 argmax 전문가의 확률만 gate value로 쓴다. 따라서 비-target 전문가의 나눗셈은 불필요 → 라우팅에 따라 동적으로 skip.
6실험 결과
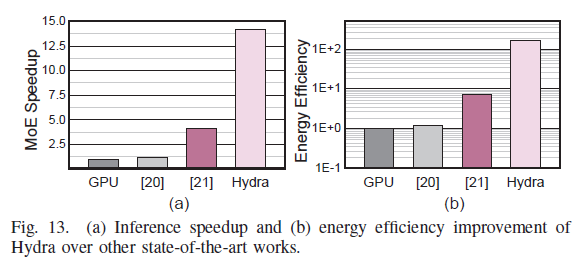
22 nm CMOS, 4×4 칩렛(각 칩렛 16 PE array·10.49mm²·934.65mW @500MHz). 모델: Switch Transformer(switch-base-8/16), FP16, C4. 비교: RTX 3090 GPU·Xeon CPU·A100 멀티GPU·SOTA 가속기(Pre-gated MoE, FLAME).
6.1 지연 · 전력 (vs GPU/CPU)
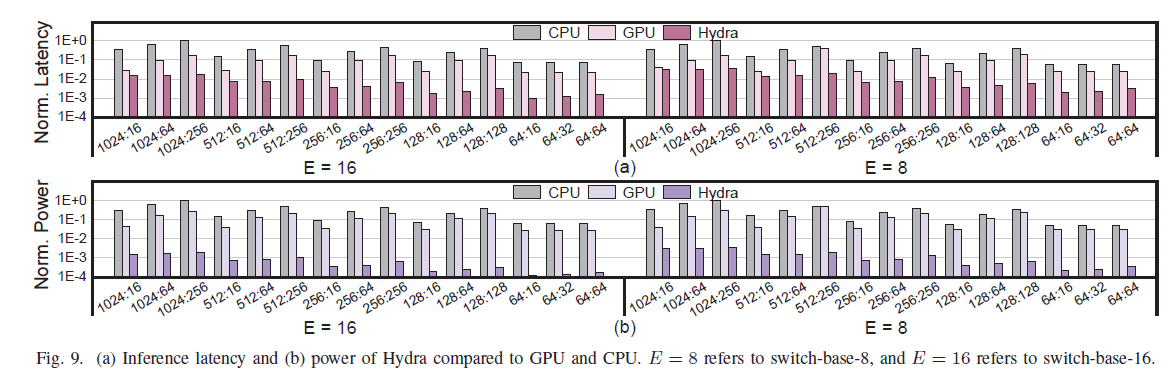
- vs RTX 3090 GPU: 지연 14.2×↓, 전력 169.1×↓.
- vs Xeon CPU: 지연 42.4×↓, 전력 357.5×↓.
- vs 멀티 A100: 4·8 GPU 대비 처리량 11.0×·11.2×↑, 에너지효율 312.2×·588.1×↑. (8GPU가 4GPU보다 못한 건 통신·자원경합 때문.)
6.2 Ablation — 세 기법의 기여
6.3 확장성 · SOTA 가속기 비교
확장성: 칩렛 수 C가 전문가 수 E 이하면 칩렛당 E/C 전문가, C>E면 expert-model 하이브리드 병렬로 전문가를 C/E 칩렛에 분산. 매핑이 대역폭을 최적화해 칩렛을 늘려도 효율적으로 확장된다.
7한계 & 의의
- 의의: MoE 전용 첫 칩렛 시스템. 통념(통신/연산을 따로 봄)을 넘어 SW(인기도 매핑) + HW(CAM·softmax)로 통신·연산 두 병목을 동시에 공략. 특히 layer 간 전문가 상관성을 예측에 활용한 점이 새롭다. 모두 무손실.
- 실용성: Simba식 2D 칩렛 그리드 + GRS 인터커넥트(방향당 100Gb/s)로 확장 가능. mapping solver를 칩렛에 내장해 prefetch와 오버랩.
- 한계: ① 인기도 예측이 사전 측정한 조건부확률에 의존 — 도메인/모델이 크게 달라지면 재측정 필요. ② Switch Transformer(encoder-decoder, top-1) 위주 평가로 top-K·decoder-only 대형 MoE에서의 일반화는 미검증. ③ simulated annealing은 휴리스틱이라 전역 최적 보장 없음. ④ 22 nm 시뮬레이션 기반(behavioral simulator + Noxim/Virtuoso), 실리콘 검증은 아님.
8핵심 용어
MoE / 게이팅 — FFN을 전문가로 나누고 토큰마다 일부 전문가만 활성화하는 희소 구조. 라우터가 argmax로 전문가 선택.
칩렛 / MCM — 작은 다이(칩렛) 여러 개를 인터포저로 연결한 멀티 칩렛 모듈. 단일 칩 메모리 한계를 넘는다.
all-to-all (dispatch/gather) — 토큰을 담당 전문가 칩렛으로 보내고(dispatch) 결과를 회수(gather)하는 집합통신. MoE layer 최대 병목.
(un)permutation — 토큰을 전문가별로 묶고(perm) 원래 순서로 되돌리는(unperm) 단계. sparse matmul이라 O(S²M).
전문가 인기도(popularity) — 한 칩렛에서 각 전문가로 향하는 토큰 빈도. 인접 layer 조건부확률로 미리 예측(식 1).
CAM — Content Addressable Memory. 저장된 모든 행을 검색키와 한 번에 비교(병렬검색)해 위치를 bitmask로 반환.
token-wise / expert-wise skipping — 모델병렬로 중복된 토큰(1/MP만 계산) / 비-target 전문가 나눗셈을 건너뛰는 무손실 softmax 최적화.
simulated annealing — 온도를 식히며 swap을 반복해 조합 최적화 비용을 낮추는 휴리스틱. 전문가↔칩렛 매핑 탐색에 사용.
✎내 메모
이 논문을 읽고 떠오른 생각·질문·아이디어를 적어두세요. 이 기기 브라우저에 자동 저장됩니다.