GRACE-MoE: 그룹핑·복제와 지역성 인식 라우팅으로 분산 MoE 추론 가속
ICLR'26 (under review) · 코드 공개 예정 (accept 시)
🎯 한 문단 요약
MoE를 여러 GPU·노드에 쪼개 추론하면 두 가지가 발목을 잡는다 — 전문가 사이를 오가는 All-to-All 통신 오버헤드와, hot/cold 전문가 때문에 생기는 GPU 계산 부하 불균형. 게다가 둘은 트레이드오프라 하나를 줄이면 다른 게 나빠진다. GRACE-MoE는 이를 ① affinity 기반 비균일 계층 그룹핑(통신↓), ② 부하 쏠림 기반 동적 hot-expert 복제(부하↓), ③ 지역성 우선 라우팅(로컬 복제본 우선)의 3단으로 동시에 풀었다. 정확도 손실 없이 end-to-end 최대 3.79× 가속, 멀티노드에서 특히 강하다.
※ "통신을 줄이면 부하가 나빠지고, 부하를 맞추면 통신이 늘어난다"는 기존의 딜레마를 동시에 해결한 게 핵심. 정확도 저하 없음.
★핵심 3대 질문
① 무슨 문제를 정의했나 · ② 무엇이 어려웠나 · ③ 어떤 구체적 방법으로 풀었나
① 어떤 문제를 정의했나
파라미터가 단일 GPU를 넘는 SMoE를 여러 GPU·노드에 쪼개 추론할 때의 end-to-end 지연을 줄이는 것. 지연의 두 원인은 (1) 전문가 간 All-to-All 통신 오버헤드와 (2) hot/cold 전문가로 인한 GPU 계산 부하 불균형이며, 특히 대역폭이 낮은 멀티노드(cross-node) 환경에서 둘을 함께 푸는 것이 목표.
② 무엇이 어려웠나
- 통신이 주 병목: 크로스노드에서 All-to-All이 MoE layer의 70%+, 전체 추론의 ~40%.
- 부하 불균형: 게이팅이 토큰을 편향 → 일부 GPU 과부하, 병렬 속도는 가장 느린 장치에 묶임.
- 결정적 충돌: 통신 줄이려 친한 전문가를 모으면 그 GPU가 과부하↑ / 부하 맞추려 흩으면 통신↑ — 한쪽 최적화가 다른 쪽을 악화.
- 2차 부작용: affinity대로 묶으면 그룹 크기가 불균일해져 부하가 더 나빠지고, 과도한 복제는 시스템을 data parallelism처럼 만들어 역효과+메모리 낭비.
- 미개척: 기존 연구는 대부분 한쪽만, single-node 위주 → 멀티노드 joint 최적화가 비어 있음.
③ 어떤 방법으로 풀었나
- 통신↓ (그룹핑): affinity 기반 비균일 계층 그룹핑 — spectral clustering + 비율
r의 knee point로 크기 제어, 노드 간은 완전 비균일·노드 내는 제어된 비균일. - 부하↓ (복제): 부하 쏠림
ρ=Wmax/W̄기반 동적 복제 — 최대부하 그룹의 hot 전문가만 골라 가장 덜 쓰는 GPU에 사본 배치. - 동시 달성 (라우팅): 지역성 우선(같은 GPU>같은 노드>노드 간) + 부하예측 가중 라운드로빈으로 통신과 부하를 함께 잡음.
1배경: 분산 SMoE 추론
Sparse MoE(SMoE)는 파라미터를 여러 전문가로 나누고 토큰마다 일부만 활성화해 "큰 파라미터, 작은 연산"을 가능케 한다. 하지만 파라미터가 단일 GPU 메모리를 넘어서면 전문가들을 여러 GPU에 쪼개 배치(expert parallelism)해야 하고, 보통 data parallelism과 결합한다.
이때 각 MoE layer는 두 번의 All-to-All 통신이 필요하다: 토큰을 담당 전문가로 보내고(dispatch), 결과를 다시 모은다(combine). 이게 수십 개 layer에서 반복되며 지연이 누적된다.
2두 가지 병목, 그리고 충돌
- ① 통신 오버헤드 — 대역폭이 낮은 크로스노드에서 All-to-All이 단일 MoE layer의 70% 이상, 전체 추론의 약 40%를 차지. SMoE 추론의 주된 병목.
- ② 계산 부하 불균형 — 게이팅 네트워크가 토큰을 편향되게 보내 "hot/cold 전문가"가 생김. 일부 GPU는 과부하, 일부는 놀게 됨. 병렬 추론 속도는 가장 느린 장치에 묶이므로 손해가 큼.
3핵심 관찰 (설계의 근거)
- 전문가 affinity 존재: top-k 라우팅에서 전문가들은 무작위가 아니라 함께 활성화(co-activation)되는 경향이 뚜렷. 어떤 전문가는 많은 전문가와 넓게, 어떤 전문가는 소수와만 친함 → affinity대로 묶으면 자연히 그룹 크기가 불균일해짐.
- 비균일 그룹핑이 통신을 줄인다: 균일 그룹핑은 자연스러운 affinity를 깨뜨림. 균일성 제약을 풀수록(=비균일) 친한 전문가가 같은 GPU에 모여 크로스 디바이스 통신이 크게 감소. (논문 Figure 1a)
- 부하는 소수에 집중: 그룹핑 후엔 layer마다 소수의 그룹이 토큰 대부분을 처리하고, 그 과부하도 소수의 자주 쓰이는 전문가에서 비롯됨. (논문 Figure 3)
- 복제는 "넓게 협업"보다 "많이 활성"을 골라야: 자주 활성화되는 전문가를 복제해야 부하가 잘 분산됨(넓게 협업한다고 다수 토큰이 선택하는 건 아니므로). (논문 Figure 1b)
→ 이 관찰들이 곧 방법의 3축(비균일 그룹핑 · hot expert만 복제 · 지역성 라우팅)으로 이어진다.
4방법: GRACE-MoE
프레임워크는 오프라인(프로파일링 → 그룹핑 → 복제)과 온라인(라우팅) 두 단계로 나뉜다. 프로파일링에서 layer별 전문가 선택을 기록해 affinity 행렬과 부하 통계를 만든다.
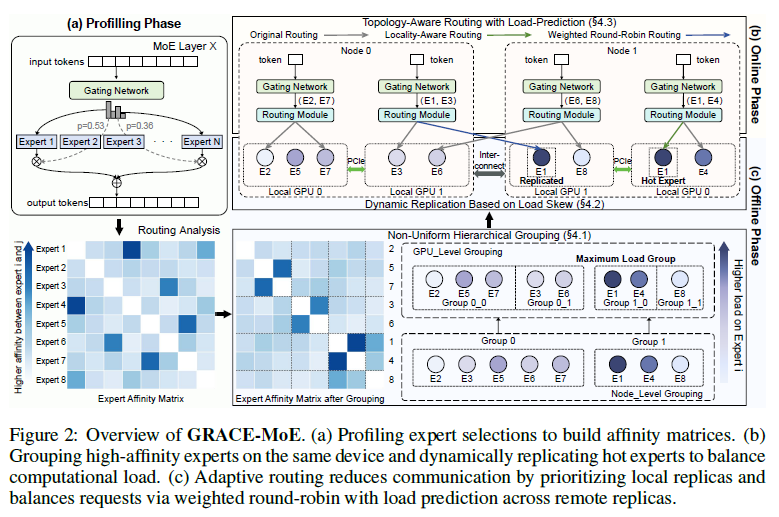
4.1 전문가 그룹핑 — 통신 중심
목표: 친한 전문가를 같은 GPU에 모아 크로스 디바이스 통신을 줄인다. affinity 행렬에 spectral clustering을 적용(내부는 촘촘, 그룹 간은 희소).
- 완전 비균일으로 묶으면 통신은 최소지만 부하 불균형이 균일보다 더 심해짐.
- 그래서 제어된 비균일(controlled non-uniform): 비균일성 비율
r로 그룹 크기를[E−δ, E+δ](δ=E·r) 안으로 제한.r이 너무 작으면 친한 전문가가 쪼개져 통신↑, 너무 크면 크기 격차로 부하↑. affinity 활용도 U(r)와 크기편차 S(r)의 knee point로 최적r선택. - 계층적 그룹핑: 노드 간은 통신이 비싸므로 완전 비균일로 나눠 크로스노드 트래픽 최소화, 노드 내부는 제어된 비균일로 크기 균형. → affinity는 GPU 안에서 최대, 같은 노드 GPU끼리는 약하게, 노드 간은 드물게.
4.2 전문가 복제 — 부하 균형 중심
그룹핑은 통신을 줄이지만 부하 불균형을 키운다. 이를 동적 복제로 완화한다.
- 무엇을: 최대 부하 그룹 안에서 hot(자주 활성) 전문가만 복제(그룹 전체 아님) → affinity·통신 이점 보존하며 중복 낭비 방지.
- 몇 개를: 부하 쏠림 계수
ρ = Wmax/W̄로 결정 →nreplica = min( max(1, ⌊ρ⌋), ngpu−1 ). 누적 부하가Wmax·nreplica/(1+nreplica)를 넘는 전문가를 hot으로 보고, 가장 덜 쓰이는 GPU들에 사본 배치(원본은 유지, 사본은 보조).
4.3 라우팅 — 통신·부하 동시 최적화
복제 후 같은 전문가 사본이 여러 GPU에 있으니, 어느 사본이 계산할지 정해야 한다. 통신 비용은 같은 GPU < 같은 노드 다른 GPU < 노드 간 순으로 커진다. 그래서 지역성 우선으로:
- 토큰과 같은 GPU에 사본이 있으면 그걸 선택.
- 없으면 같은 노드의 다른 GPU 사본 중에서 선택.
- 그것도 없으면 노드 간 사본으로.
각 단계에서 사본이 여러 개면 부하예측 가중 라운드로빈(WRR)으로 분산.
복제 후 GPU별 부하를 예측(식 3: W′ = W − Wr + Wp)해 예측 부하에 반비례하는 가중치로 토큰을 보낸다.
순수 WRR은 무작위성 탓에 불필요한 원격 전송을 유발하므로, 지역성 우선이 이를 막아 통신을 줄인다.
5실험 결과
모델 3종 · 데이터셋: WikiText-2 / MATH / The Pile(GitHub). 하드웨어: RTX 3090(PCIe 1.0, 4GB/s)·RTX 4090(PCIe 4.0, 63GB/s) 노드, 노드 간 25Gb 이더넷. 비교: DeepSpeed, Tutel, MegaBlocks, vLLM, C2R. batch=128, prefill=64, decode=16.
| 모델 | Top-k | 전문가 수 | MoE layers | 파라미터 |
|---|---|---|---|---|
| OLMoE | 8 | 64 | 16 | 6.92B |
| DeepSeek-v2-lite-chat | 6 | 64 | 26 | 15.7B |
| Qwen3-30B-A3B | 8 | 128 | 48 | 30.5B |
전체 성능 (End-to-End)
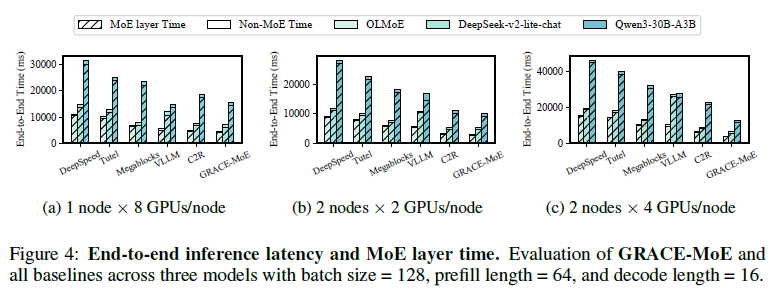
모든 baseline 대비 일관되게 우위. MoE layer 시간 2.1~75.5%↓, 전체 속도 0.95~3.79×. 노드·GPU가 늘수록 baseline은 통신 때문에 지연이 급증하지만, GRACE-MoE는 멀티노드에서 MoE layer 최대 75.5%↓, end-to-end 최대 73.6%↓로 확장성이 강하다.
컴포넌트 분석 (왜 되는가)
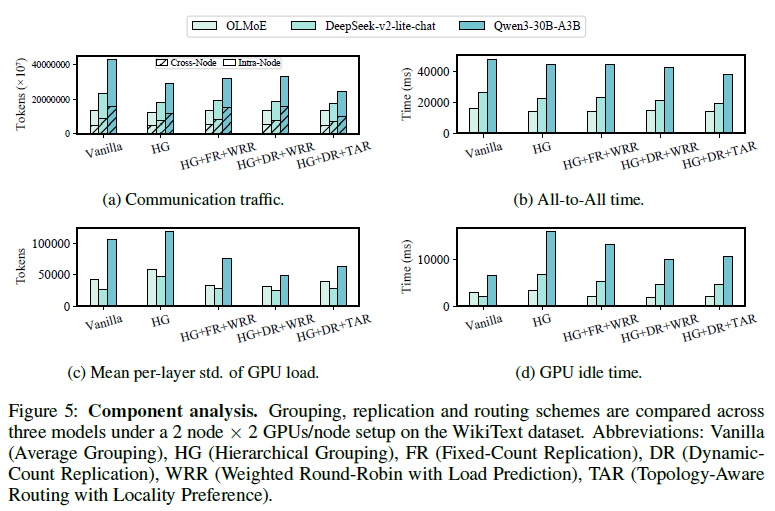
- RQ1 통신↓ (Vanilla→HG): All-to-All 시간 −14.3 / 15.2 / 7.6%, 크로스노드 −3.3 / 14.6 / 26.0%, 노드 내 −10.0 / 25.1 / 35.8% (3개 모델).
- RQ2 부하↓: HG만 쓰면 idle·부하편차가 오히려 ↑. 여기에 동적복제+WRR를 더하면 HG 대비 idle −43.3 / 32.3 / 37.8%, 부하편차 −44.8 / 48.0 / 58.3%로 크게 개선(고정복제보다 우수).
- RQ3 동시 최적화: WRR은 무작위성으로 통신을 되레 늘림(크로스노드 +17.7%). TAR(지역성 우선)를 쓰면 WRR 대비 All-to-All −2.8 / 8.3 / 10.0%, 크로스노드 −6.3 / 11.6 / 35.2%를 회복하면서 idle·부하편차는 소폭(+5.25%, +21.4%)만 증가 → 유리한 트레이드오프.
최종적으로 2노드×2GPU에서 end-to-end −66.5 / 54.7 / 64.5%, 속도 2.98× / 2.21× / 2.81×.
6한계 & 의의
- 의의: 그동안 따로 다뤄지던 통신 오버헤드와 부하 불균형을, 멀티노드 환경에서 하나의 프레임워크로 동시에 최적화. affinity 기반 비균일 그룹핑은 이 논문이 처음 제안.
- 실용성: 정확도 손실 없음. Megablocks + PyTorch 2.5 + Triton 3.0 위에 구현, data+expert 병렬 추론 지원.
- 한계: ① 복제가 메모리를 추가로 소모 → 메모리가 빠듯한 GPU에선 제약(향후 model splitting·expert sharing으로 보완 가능). ② 평가가 학술용 하드웨어·중간 규모 모델에 한정 → 더 큰 모델·산업용 클러스터 검증은 향후 과제.
7핵심 용어
SMoE / Expert Parallelism — 전문가들을 여러 GPU에 분산 배치하는 병렬화.
All-to-All — 토큰을 담당 전문가로 보내고 결과를 모으는 집합 통신. MoE layer마다 2회.
Expert affinity / co-activation — 특정 전문가들이 함께 자주 활성화되는 경향.
Spectral clustering — 그래프(affinity)를 내부 촘촘·외부 희소한 그룹으로 나누는 군집화.
Non-uniform grouping — 그룹 크기를 균일하게 강제하지 않고 affinity대로 묶는 방식.
Hot expert — 토큰이 많이 몰리는, 자주 활성화되는 전문가.
Load skew (ρ) — 최대부하/평균부하 = Wmax/W̄. 복제 개수 결정에 사용.
Locality / Topology-aware routing — 같은 GPU→같은 노드→노드 간 순으로 가까운 사본을 우선 선택.