FineMoE: 토큰 스케줄링과 선형계획법으로 MoE를 미세 부하균형하기
arXiv:2511.16947v2 (2026-01) · Megatron-LM 위에 구현 · GPT/Mixtral로 평가
🎯 한 문단 요약
MoE 학습은 게이트가 토큰을 일부 전문가에 편향되게 보내 GPU마다 부하가 들쭉날쭉해진다. Expert Parallelism(EP)에서는 모든 GPU가 가장 무거운 GPU(straggler)를 기다려야 해서 처리량이 깎인다. 기존 해법은 라우팅을 바꿔 정확도를 희생하거나, 전문가(파라미터)를 옮겨 무거운 시스템 오버헤드를 낸다. FineMoE는 발상을 뒤집어 전문가가 아니라 토큰을 스케줄링한다. 같은 전문가의 여러 복제본(EDP group)을 활용해 매 micro-batch마다 선형계획법(LP)으로 토큰을 재분배해 GPU 최대 부하를 최소화하고, 전문가 배치를 섞어(그래프 이론으로 분석) 스케줄링 공간을 넓혀 전역 균형을 달성한다. 정확도 손실·파라미터 이동 없이, Megatron-LM 대비 학습 처리량 최대 47.6%↑(평균 36.9%↑).
※ 핵심: 토큰 스케줄링은 토큰 수 단위로 GPU 부하를 연속적으로 조절할 수 있어 "완전 부하균형"에 도달. 게다가 EP의 기존 all-to-all 통신을 그대로 써서 통신 추가비용이 거의 없다.
★핵심 3대 질문
① 무슨 문제를 정의했나 · ② 무엇이 어려웠나 · ③ 어떤 구체적 방법으로 풀었나
① 어떤 문제를 정의했나
MoE 학습에서 전문가 사이 부하 불균형을 없애 EP의 straggler 문제를 제거하고 학습 처리량을 올리는 것. 그것도 정확도를 건드리지 않고(systematic), 매 micro-batch 단위로 미세하게(fine-grained·dynamic) 달성하는 것이 목표.
② 무엇이 어려웠나
- R1 — 미세함 필요: GPU가 수백~수천 개라 작은 불균형도 큰 낭비. 기존 expert 단위 스케줄링은 이산적이라 가능한 부하분포 공간이 듬성듬성 → 최적 균형 불가.
- R2 — 동적 적응 필요: 전문가 부하가 micro-batch마다 크게 출렁임. 그런데 기존 방식은 전문가 파라미터 자체를 이동시켜야 해서 매번 조정하기엔 너무 무겁다.
- C1 — 스케줄링 공간 없음: Vanilla EP는 토큰을 EP group 안으로만 보내고, group엔 전문가 복제본이 정확히 1개뿐 → 토큰→GPU 매핑이 게이트에 의해 고정됨.
- C2 — 공간이 좁음: 모든 EP group이 동일한 전문가 배치를 쓰면 EDP group들이 서로 겹치지 않아 국소 균형만 가능, 전역 불균형은 남는다.
③ 어떤 방법으로 풀었나
- 토큰 스케줄링(발상 전환): 전문가 대신 토큰을 옮긴다. 같은 전문가의 복제본 집합(EDP group)이 곧 스케줄링 공간 → 토큰 수 단위로 연속적 부하조절(R1·C1 해결).
- LP로 매 micro-batch 최적화: "GPU 최대부하 최소화"를 선형계획법으로 풀어 복제본별 부하를 결정. EP의 기존 all-to-all을 재사용해 통신비 거의 0(R2 해결).
- 전문가 배치 섞기 + 그래프 이론: EP group들을 병합하고 배치를 셔플해 EDP group이 서로 교차하게 만들어 공간을 넓힘. "최적 배치 = 최대 유도부분그래프 밀도가 최소인 그래프"로 정식화(C2 해결).
1배경: MoE·EP와 straggler
MoE(Mixture-of-Experts)는 FFN을 여러 전문가로 나누고, 게이트가 각 토큰을 가장 알맞은 top-K 전문가에만 보내는 희소 구조다. 파라미터는 키우되 연산은 sub-linear로만 늘려 GPT-5·Llama 4·DeepSeek-V3 등 SOTA가 모두 채택했다.
분산 학습에선 Expert Parallelism(EP)으로 전문가들을 여러 GPU에 흩는다. 각 MoE layer는 토큰을 담당 전문가로 보내고(all-to-all dispatch) 결과를 다시 모으는(combine) 두 번의 집합통신이 필요하다.
2왜 어려운가 (기존 해법의 한계)
- 알고리즘적 해법(load-balancing loss·토큰 드롭·차선 전문가로 라우팅)은 모델 로직을 바꿔 정확도·수렴을 해친다 → 정확도 vs 효율 트레이드오프.
- 전문가 스케줄링 해법(FlexMoE·SmartMoE 등, expert-to-GPU 매핑 조정)은 정확도는 지키지만:
- R1 위반: 전문가(복제본)를 스케줄링 단위로 삼아 이산적 → 가능한 부하분포가 듬성듬성, 최적 균형 불가.
- R2 위반: 부하변화에 맞추려면 큰 전문가 파라미터를 이동해야 해 micro-batch마다 조정하기엔 너무 무겁다.
토큰 스케줄링으로 가려 해도 두 장벽이 있다:
C2 모든 EP group이 동일 배치를 쓰면 서로 다른 전문가의 EDP group이 완전히 같거나 완전히 분리됨 → EDP group 내부만 맞출 수 있어 국소 균형에 그침.
3핵심 아이디어: EP → FineEP
FineMoE의 전략 FineEP는 세 걸음으로 vanilla EP를 바꾼다. 아래 그림이 전부를 보여준다.
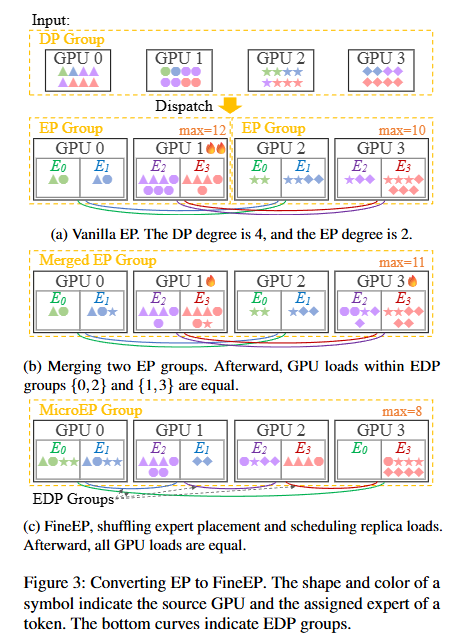
- 병합(Solution 1, C1 해결):
d개의 EP group을 하나의 FineEP group으로 묶는다. 같은 전문가의 복제본은 어디서 계산해도 동일하므로, 복제본들 사이로 토큰을 배분할 스케줄링 공간이 생긴다. - 셔플(Solution 2, C2 해결): 병합된 group 안에서 전문가 배치를 섞는다. 그러면 서로 다른 전문가의 EDP group이 교차해 스케줄링 공간이 크게 넓어지고, 국소가 아닌 전역 부하균형이 가능해진다.
- 스케줄(매 micro-batch): 게이트가 토큰을 전문가에 배정한 뒤, dispatcher가 토큰을 그 전문가의 특정 복제본으로 라우팅. 통신 패턴은 vanilla EP와 같되 group 크기만
d배.
4토큰 스케줄링 = 선형계획법(LP)
스케줄링은 두 단계다: ① 복제본별 부하 결정(LP) → ② 토큰을 실제 복제본에 배정(라우팅).
4.1 복제본 부하 결정 — LP로
변수 xge = GPU g에 놓인 전문가 e의 부하. 제약은 "각 전문가는 자기 총부하 loade를 복제본들에 모두 나눠 가진다". 목적은 GPU 최대부하 최소화(동기화 때문에 최대부하가 곧 병목).
이건 선형계획문제(LPP)라 다항시간에 풀린다. 변수 O(|E|·d), 제약 O(|E|+|GPU|)로 규모가 작아 CPU 단일 스레드 HiGHS 솔버로 충분. micro-batch마다 제약행렬(=전문가 배치)은 그대로고 부하 loade만 바뀌므로 직전 해를 재활용하는 warm-start로 오버헤드를 크게 줄인다.
4.2 토큰 라우팅 — 지역성 우선
계산된 xge를 지키도록 토큰을 순차 배정한다. all-to-all 통신량을 줄이려고
locality-aware routing: GPU g가 전문가 e의 복제본을 가지면, g의 토큰을 로컬 복제본에 먼저 채우고 남는 것만 원격으로 보낸다(Algorithm 1).
4.3 어디서·언제 — 분산 + 오버랩
- 분산 스케줄러(§5.3): 모든 GPU가 all-gather로 전역 부하정보를 모아 각자 독립 실행. 알고리즘이 결정적이라 결과가 일치하고, 통신 1회로 끝나 중앙집중(2회)보다 확장성↑.
- 오버랩(§5.4): 스케줄링은 게이트 직후·all-to-all 직전에 도는데, 이때 Megatron-LM은 토큰 permutation을 GPU에서 수행 → CPU 스케줄링과 GPU permutation을 겹쳐 지연을 숨긴다. (적당한 겹칠 연산이 없으면 pipelining으로 대체, Appendix A.2)
- 통신 인식 스케줄링(Appendix A.1): 계산뿐 아니라 통신시간까지 목적함수에 넣어(intra/inter-node 가중치
α) 함께 최소화하는 확장 LP도 제시.
5전문가 배치: 그래프 이론
LP의 제약행렬은 곧 전문가 배치(EDP group)가 결정한다. 그래서 "어떤 배치가 최적인가?"가 장기적 성능을 좌우한다.
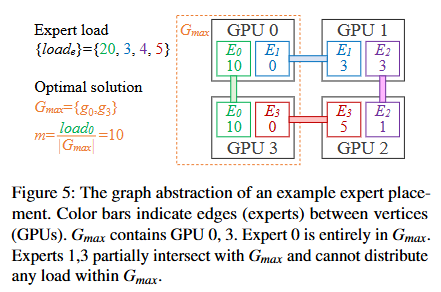
Gmax(부하 m인 GPU 집합) 안에 EDP group이 완전히 들어간 전문가만 그 안에 부하를 둘 수 있다. 최적값 m = 모든 유도부분그래프의 최대 밀도.- 대칭 배치(부하 모를 때, §6.2): 전문가를 i.i.d.로 보고 Cayley 그래프로 구성. 군(group)의 대칭성 덕에 간선이 정점에 고르게 퍼져 어떤 부분그래프도 유독 밀집하지 않음(예: 4×4 토로이달 격자, K4,4).
- 비대칭 배치(부하 알 때, §6.3): 부하에 맞춰 복제본 개수·위치를 다르게. ① load-per-replica 최대 전문가에 복제본을 그리디 할당 → ② Monte Carlo 샘플링으로 최대밀도 최소인 배치 선택.
- 적응적 재배치(AR, §6.4): placement manager가 부하를 백그라운드 모니터링, 시계열(이동평균)로 미래 부하 예측 후 식 3으로 현 배치 성능 평가 → 임계 이하로 떨어지면 새 비대칭 배치로 주기적 재초기화. 초기엔 50 iter 권장(오버헤드 <1%), 안정되면 간격↑.
→ 토큰 스케줄링(순간·미세) + 적응적 재배치(장기·거시)의 2계층. 웬만한 불균형은 정적 대칭 배치 + 토큰 스케줄링만으로 완전균형이고, 극심한 쏠림(s>1)에서만 비대칭 배치가 필요.
6실험 결과
테스트베드: 4노드 × 8× H100 80GB(NVLink 900GB/s), 노드 간 2× 400Gb IB. 모델: GPT·Mixtral(Wikipedia 사전학습). 비교: Megatron-LM, DeepSpeed, SmartMoE, FlexMoE. BF16, 토큰 드롭 비활성, 분산 옵티마이저(ZeRO-1) 사용.
6.1 End-to-End 처리량
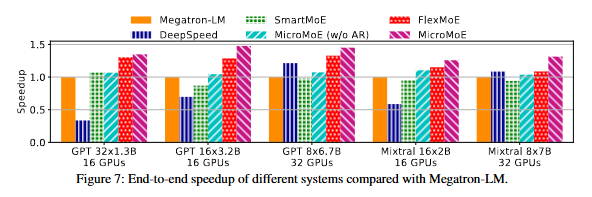
- Megatron-LM 대비 최대 +47.6%, 평균 +36.9%. 2위 FlexMoE 대비 평균 +13.9% 더 빠름.
- SmartMoE(복제 균일)는 장기 부하 기준 배치라 micro-batch엔 종종 차선 → 가끔 vanilla보다 느림. 같은 조건 FineMoE(w/o AR)가 미세 토큰 스케줄링으로 우위.
- 이미 완전균형에 도달했으므로 이 수치가 부하균형으로 얻을 수 있는 상한.
6.2 부하균형 능력
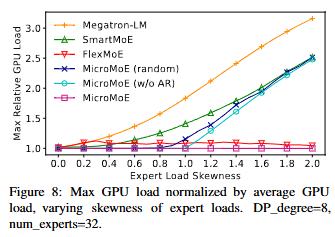
s를 키우며 본 최대 GPU부하(평균=1로 정규화, 1.0이 완전균형). SmartMoE·Megatron-LM은 왜도↑에 급증. FlexMoE는 양호하나 미세 동적성 부족. FineMoE(w/o AR)는 s<1에서 완벽 균형, FineMoE(비대칭)는 항상 완전균형.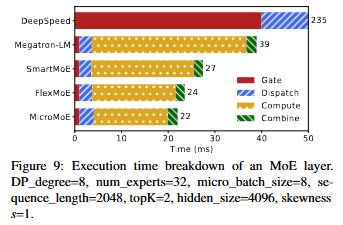
6.3 오버헤드
- 스케줄링: LP 풀이가 지배적이나 64 GPU·256 전문가에서도 <1ms, 최소 ~100µs. 최적화(warm-start·overlap·locality)를 다 켜면 vanilla Megatron-LM 대비 dispatch +0.4ms뿐이고, 줄어든 계산시간이 이를 압도.
- 재배치: 비대칭 전환은 파라미터·옵티마이저 상태 이동에 수백 ms → 너무 자주 하면 손해. 초기 50 iter, 안정 후 수백 iter(또는 0).
7한계 & 의의
- 의의: "전문가를 옮긴다"는 통념을 깨고 토큰을 옮겨 fine-grained·dynamic 부하균형을 달성. LP 정식화 + 그래프 이론으로 전문가 배치와 토큰 스케줄링의 관계를 처음으로 이론 분석. 기존 알고리즘적 해법과도 호환(정확도 무손실).
- 실용성: Megatron-LM 위에 DDP 유사 wrapper로 구현, C++ 스케줄러. NCCL·DeepEP 백엔드 지원.
- 한계: ① d배 커진 all-to-all group이 일부 통신을 inter-node로 바꿀 수 있음(단
d·EP_degree ≤ 노드당 GPU거나 EP_degree가 매우 클 때는 무시 가능). DeepEP에선 데이터 포맷 비호환으로 전처리 오버헤드가 EP보다 큼. ② 대규모로 갈수록 스케줄링 비용↑ → group 단위 스케줄링으로 절충 필요. ③ 현재 DDP 기반, FSDP 통합은 향후 과제. - 관련 동시기 연구: DeepSeek의 LPLB도 LP 기반 토큰 스케줄링이지만 분석·평가가 부족. 본 논문은 배치-스케줄링 관계 분석·다중 배치전략·locality 최적화로 차별화.
8핵심 용어
MoE / top-K 게이팅 — FFN을 전문가로 나누고 토큰마다 top-K 전문가만 활성화하는 희소 구조.
EP (Expert Parallelism) — 전문가들을 여러 GPU에 분산. layer마다 all-to-all 2회(dispatch·combine).
EDP group — 같은 전문가의 복제본들이 놓인 GPU 집합. 복제본은 동일하므로 그 안 어디서 계산해도 됨 → 스케줄링 공간의 원천.
straggler — 동기화 때문에 전체 속도를 묶는 가장 무거운 GPU.
FineEP / FineEP group — d개 EP group을 묶고 배치를 셔플한 본 논문의 EP 전략 / 그 단위.
LPP·warm-start — 최대 GPU부하 최소화를 푸는 선형계획문제. 배치 고정·부하만 변하므로 직전 해 재활용.
유도부분그래프 밀도 — (부분그래프 간선가중치 합)/(정점 수). 최적 배치는 이 최대값이 최소.
Cayley 그래프 — 군과 생성집합으로 만든 대칭 그래프. 부하 모를 때 대칭 배치 구성에 사용.