EARTH: 엔트로피 인식 speculative prefetch와 패턴 재사용 MoE 가속기
ASPLOS '26 · 10.1145/3779212.3790155 · HW–SW co-design 가속기
🎯 한 문단 요약
MoE 추론은 연산은 적지만 expert 파라미터를 메모리에서 불러오는 데이터 이동이 실행시간의 ~88%를 잡아먹는다. 특히 메모리가 빠듯한 하드웨어에서 기존 offloading/prefetch는 정확도 손실·과한 트래픽·디코딩 오버헤드에 시달린다. EARTH는 HW–SW를 함께 설계해 이를 푼다: ① 가중치를 base(상위)·delta(하위)로 쪼개는 dual-entropy 인코딩, ② base만 미리 받고 delta는 중요할 때만 받는(중간 중요도는 LUT로 재사용) speculative prefetch, ③ 이를 지원하는 전용 가속기 + match-and-action 스케줄. 정확도 거의 유지하며 최대 2.10× 가속.
★핵심 3대 질문
① 무슨 문제를 정의했나 · ② 무엇이 어려웠나 · ③ 어떤 구체적 방법으로 풀었나
① 어떤 문제를 정의했나
메모리가 제한된 하드웨어에서 MoE 추론을 효율적으로 돌리기. MoE는 expert 파라미터가 너무 커서 전부 온칩에 못 올리고, expert를 불러오는 데이터 이동이 추론 지연의 ~88%를 차지하는 진짜 병목이다. 정확도를 지키면서 이 fetch 비용을 줄이는 게 목표.
② 무엇이 어려웠나
- 다중 정밀도의 비용: expert마다 민감도가 다른데(어떤 건 견고, 어떤 건 취약), INT8/INT4를 둘 다 저장하면 용량·전송이 2배. 그냥 상위 비트만 자르면 정보 손실이 큼.
- 버퍼 한계: 온칩 버퍼가 작아 한 번에 소수 expert만 캐시 → 잦은 재로딩.
- 예측의 한계: 정적/휴리스틱 prefetch는 동적 라우팅을 못 따라가 hit율이 낮고 파이프라인 stall.
- 병목 이동: base만 미리 받아 잘 풀어도, 이번엔 delta가 로드 시간의 >60%를 차지하는 새 병목이 됨.
③ 어떤 방법으로 풀었나
- dual-entropy 인코딩: INT8 가중치를 high-info base 4비트 + delta 4비트로 분해(엔트로피가 상위 비트에 집중) → 한 벌만 저장하고 정밀도를 슬라이스로 조절.
- delta-aware speculative prefetch & reuse: 예측 expert의 base만 미리 로드, 중요 expert만 delta 즉시 fetch, 비중요는 base만, 중간 중요도는 LUT로 delta 패턴 재사용(DRAM 접근 제거).
- 전용 가속기 + match-and-action: bit-interleaved 저장으로 온칩 expert 수를 2배로, delta 디코딩을 PE 연산과 오버랩해 stall 제거.
1배경 & 문제: fetch가 88%
MoE는 토큰마다 일부 expert만 켜서 연산을 줄이지만, expert 파라미터 수가 워낙 많아(같은 FLOPs dense 대비 최대 75×) 단일 가속기 메모리를 넘어선다. 그래서 자주 안 쓰는 expert를 느린 메모리(CPU/NVMe)로 내리고 필요할 때 가져오는 offloading을 쓰는데, 그 불러오기(fetch)가 병목이다.
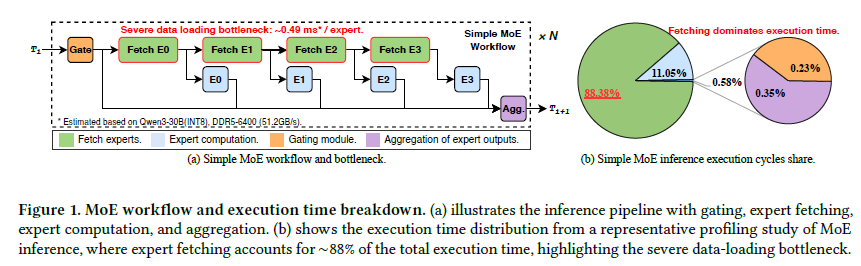
2관찰: 설계의 근거
관찰 1 — expert마다 민감도가 다르다
가중치에 노이즈를 주입해 출력 변화를 보면, 같은 layer 안에서도 expert별 견고성 편차가 크다. 견고한 expert(예: Expert 0)는 노이즈에도 출력이 유지되지만, 취약한 expert(예: 6·7)는 작은 노이즈에도 급격히 망가진다. → 견고한 expert는 더 거칠게 양자화해도 된다는 기회.
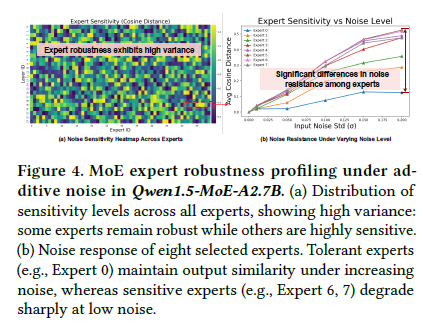
또한 INT8의 상위 비트는 수치 범위를 정하지만 정보 엔트로피는 낮다(상위 비트에 정보가 집중). 이래서 가중치를 base(상위)·delta(하위)로 쪼개는 게 정당화된다.
관찰 2 — prefetch는 효과적이지만 용량 제약
prefetch 예산을 키우면 단계당 로드할 expert 수가 준다(예: DeepSeek-V2-Lite에서 윈도우 6→16일 때 평균 로드 5.22→4.09). 하지만 온칩 메모리·대역폭이 한계다. → 가장 정보가 많은 슬라이스(base)만 미리 받으면 같은 예산으로 더 많은 expert를 prefetch할 수 있다.
3방법: 인코딩 → prefetch → 재사용
3.1 Dual-entropy 인코딩
INT8 가중치 w를 4비트 base w_b(상위)와 4비트 delta w_d(하위)로 분해: w = (w_b << 4) + w_d. 상위 비트에 정보(엔트로피)가 집중돼 있어 base만으로도 상당한 정밀도를 낸다. 4/4 분할은 1바이트 정렬·PE 폭에 맞아 하드웨어 친화적.
3.2 Delta-aware speculative prefetch
게이팅의 라우팅 이력으로 다음 토큰의 expert를 예측해 base만 FIFO 버퍼에 미리 올린다. 실제 라우팅이 정해지면 3가지로 분기:
- Hit + 중요 expert(게이팅 가중치 ≥ 임계): delta를 마저 fetch해 풀정밀도 계산.
- Hit + 비중요 expert: delta를 건너뛰고 base만 사용 → 전송 절약(정확도 영향 미미).
- Miss: 올바른 expert의 base만 로드(delta는 애초에 투기적으로 안 받았으니 페널티 최소).
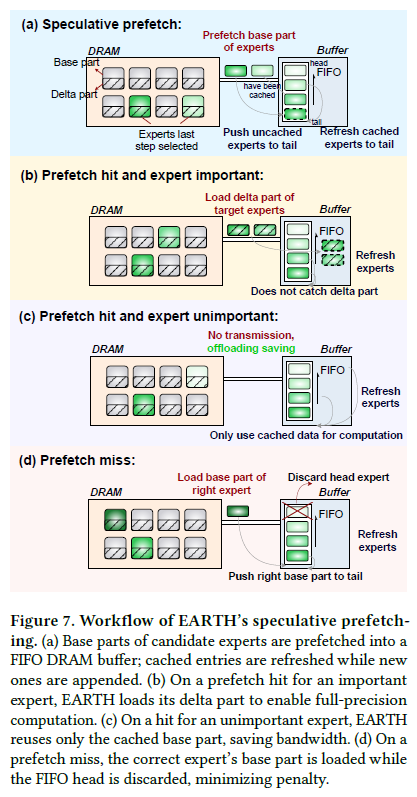
임계값은 오프라인 보정 — delta 생략으로 인한 정확도 저하가 1%를 넘지 않게.
3.3 Delta가 새 병목 → 패턴 재사용(LUT)
base를 잘 처리하고 나면 이제 delta가 로드 시간의 >60%를 차지한다. 그런데 ⟨base, delta⟩ 패턴이 매우 반복적이다 — 예를 들어 base가 1111인 경우 92.86%가 단 두 패턴이고, 고유 패턴은 모델 크기와 무관하게 수십 개뿐이다.
⟨base→delta⟩를 LUT(코드북)로 만들어 둔다. 중간 중요도 expert는 fetch한 base로 LUT를 조회해 delta를 DRAM 없이 복원 → delta 트래픽 대폭 감소. LUT는 수십 엔트리라 면적 부담이 거의 없다.4아키텍처 & 실행 스케줄
EARTH 가속기는 16개 PE(각 16 DPU)로 된 compute core, base/delta로 나뉜 bit-interleaved weight buffer, 게이팅 모듈, 전용 dispatcher들로 구성된다. 런타임엔 W_base와 LUT 엔트리만 가져와 필요할 때 W_delta를 복원(디코딩을 미룸).
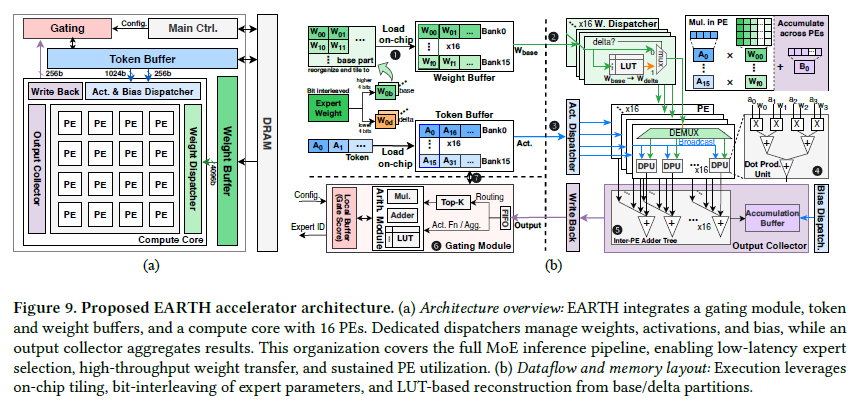
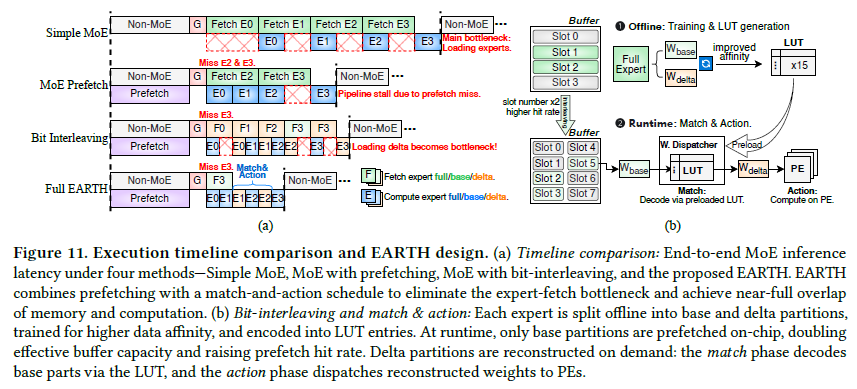
Match-and-Action 타임라인
단순 MoE는 fetch가 PE를 놀린다. prefetch는 일부 완화하나 버퍼·miss에 막히고, bit-interleaving은 hit율은 올리지만 delta fetch가 여전히 stall을 만든다. EARTH는 base만 prefetch해 온칩 expert 수를 2배로 늘리고, match(LUT로 base 디코딩) → action(복원 가중치를 PE로 디스패치)을 연산과 겹쳐 파이프라인 버블을 없앤다.
5실험 결과
RTL(Verilog, TSMC 28nm, 250MHz) + cycle-accurate 시뮬 + CACTI 메모리 모델. 16 PE, 16MB weight buffer, HBM2E 256GB/s. 모델: Mixtral-8x7B / Qwen1.5-MoE-A2.7B / DeepSeek-V2-Lite. baseline: EdgeMoE·AdapMoE·DAOP·HybriMoE·APTMoE.
End-to-end 속도 (CER = 캐시 가능한 expert 비율)
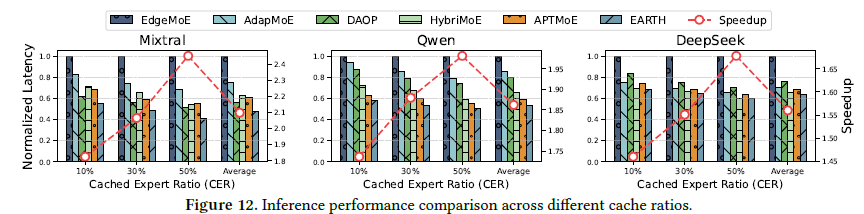
| 모델 | 이상 speedup | 실제 speedup | 이상 대비 | compute-transfer overlap |
|---|---|---|---|---|
| Mixtral | 2.32× | 2.10× | 90.5% | 89% |
| Qwen | 2.21× | 2.06× | 93.2% | 91% |
| DeepSeek | 1.83× | 1.72× | 94.0% | 86% |
구성요소 기여 (ablation) & 정확도
- naive prefetch 1.12× → +entropy-aware speculative prefetch 1.52× → +delta 재사용(full EARTH) 2.06×.
- 중요 expert를 80~90% 유지하면 정확도 손실 거의 없이 로드 20%+ 감소; DeepSeek은 긴 시퀀스에서 패턴 반복이 커 최대 40% 로드 감소.
- EARTH 데이터 포맷은 20~25% expert를 근사해도 정확도 1% 이내 유지(단순 INT 절단은 10% 넘으면 급락).
- 층별 적응 재사용(초기 층 20~35%, 깊은 층 최대 70%)로 평균 1.36× 가속, Rouge-L 24.7 유지(고정 재사용 21.3 대비↑).
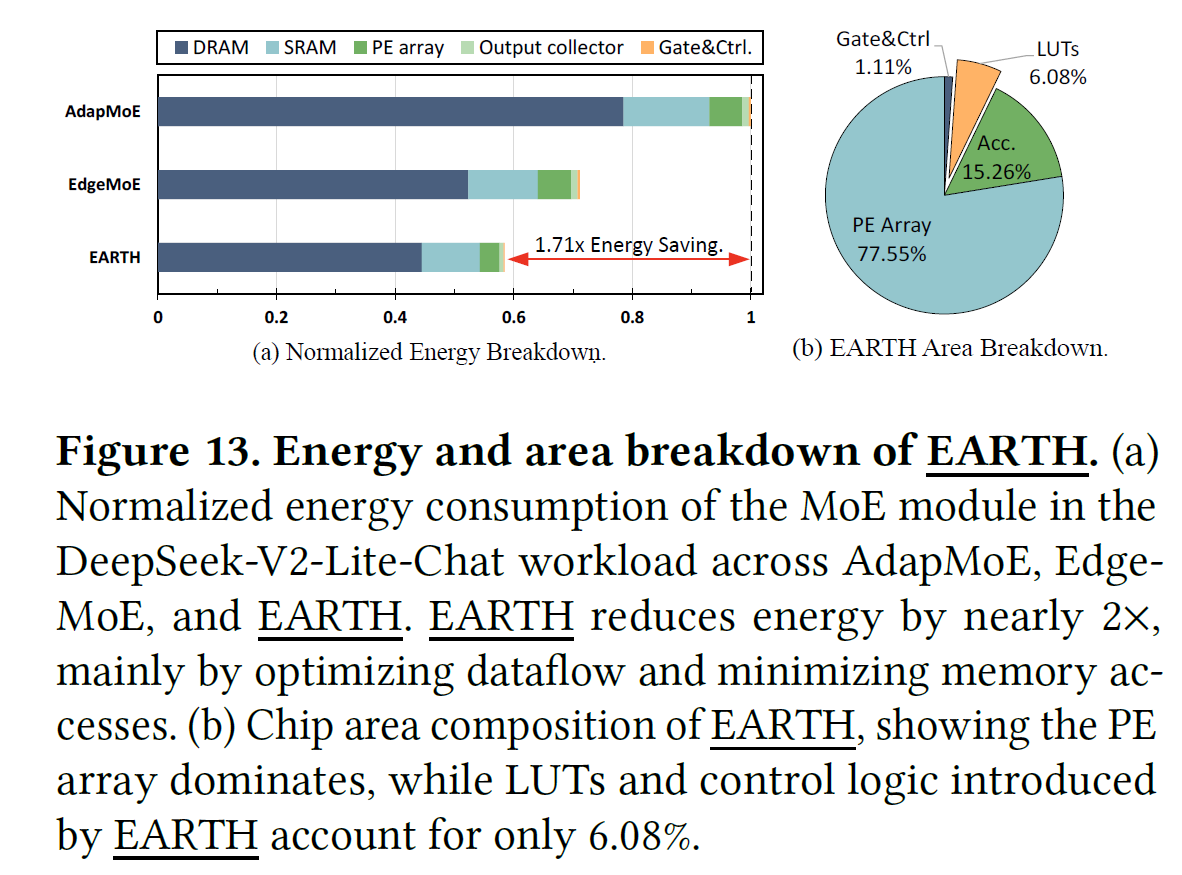
에너지 & 면적
6한계 & 의의
- 의의: 범용 가속기·기존 MoE 가속기가 놓친 데이터 이동(불규칙 expert 접근·동적 라우팅)이라는 진짜 병목을 정조준. 모델 재학습·구조 변경 없이 인코딩+prefetch+재사용을 하드웨어로 통합해 메모리·에너지·속도를 동시 개선. LUT가 모델 크기와 무관해 확장성 좋음.
- 한계: INT8을 4/4로 나누는 전제(다른 정밀도 일반화는 추가 설계 필요). 공격적 delta 생략·재사용은 정확도와 트레이드오프(중요 expert delta를 30% 넘게 생략하면 품질 저하). 평가는 전용 RTL/시뮬 + 중간 규모 모델 범위.
7핵심 용어
Offloading — 안 쓰는 expert를 느린 메모리(CPU/NVMe)에 두고 필요 시 가져오는 기법.
Prefetch — 쓰일 것 같은 expert를 미리 불러와 fetch 지연을 숨김.
Dual-entropy 인코딩 — 가중치를 정보 많은 base(상위)·보정용 delta(하위)로 분해.
Expert sensitivity — 양자화/노이즈에 대한 expert별 취약도. 높을수록 정밀도 보존 필요.
Gating weight — 게이팅이 매기는 expert 중요도 점수. delta를 받을지 결정에 사용.
LUT 패턴 재사용 — 반복되는 ⟨base→delta⟩를 표로 만들어 delta를 DRAM 없이 복원.
Match-and-Action — (match) LUT로 base 디코딩 → (action) PE로 디스패치, 연산과 오버랩.
CER (Cached Expert Ratio) — 온칩에 올릴 수 있는 expert 슬롯 / 전체 expert 비율.